1. 순환 신경망(Recurrent Neural Network)
- 시계열 또는 자연어와 같은 Sequence 데이터를 모델링하는데 강력한 신경망, 시계열 데이터나 시퀀스 데이터를 잘 처리
- 예) 주식 가격, 텍스트 데이터, 오디오 데이터
- Sequence: 단어의 문장, 연결되어 있는 정보
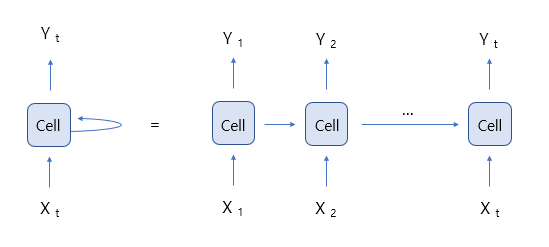
1. RNN 동작 방식 |
|
2. inupt size |
|
3. hidden state |
|
4. Sequence Length |
|
5. Batch Size |
|
◼ 간단한 RNN(Recurrent Neural Network)을 정의하고 입력 데이터를 처리
|
import torch
import numpy as np
from torch.nn import RNN
input_size = 4
hidden_size = 2
input_size = 4
hidden_size = 2
h = [1, 0, 0, 0]
e = [0, 1, 0 , 0]
l = [0, 0, 1, 0]
o = [0, 0, 0, 1]
input_data_np = np.array([[h, e, l, l, o],
[e, o, l, l, l],
[l, l, e, e, l]], dtype = np.float32)
input_data = torch.Tensor(input_data_np)
rnn = RNN(input_size, hidden_size)
outputs, state = rnn(input_data)
state
|
| tensor([[[ 0.4268, -0.1465], [ 0.5059, 0.5654], [ 0.0742, 0.1633], [ 0.0742, 0.1633], [ 0.7979, -0.0312]]], grad_fn=<StackBackward0>) |
- 주석
더보기
|
import torch
import numpy as np
from torch.nn import RNN
input_size = 4 # 입력 데이터의 크기. 각 입력 벡터의 길이입니다.
hidden_size = 2 # 은닉 상태의 크기. RNN 셀 내부의 은닉 상태 벡터의 크기입니다.
# 입력 데이터를 one-hot encoding으로 정의합니다.
h = [1, 0, 0, 0] # 'h'를 나타내는 one-hot 벡터
e = [0, 1, 0, 0] # 'e'를 나타내는 one-hot 벡터
l = [0, 0, 1, 0] # 'l'을 나타내는 one-hot 벡터
o = [0, 0, 0, 1] # 'o'를 나타내는 one-hot 벡터
# 입력 데이터를 numpy 배열로 정의합니다. shape는 (배치 크기, 시퀀스 길이, 입력 크기)입니다.
input_data_np = np.array([[h, e, l, l, o], # 첫 번째 시퀀스
[e, o, l, l, l], # 두 번째 시퀀스
[l, l, e, e, l]], dtype=np.float32) # 세 번째 시퀀스
# numpy 배열을 PyTorch Tensor로 변환합니다.
input_data = torch.Tensor(input_data_np)
# RNN 모델을 정의합니다. 입력 크기와 은닉 상태 크기를 인자로 받습니다.
rnn = RNN(input_size, hidden_size)
# 입력 데이터를 RNN에 넣어 출력을 계산합니다. outputs와 status를 반환합니다.
outputs, state = rnn(input_data)
print("입력 데이터:", input_data)
print("출력 데이터:", outputs)
print("은닉 상태:", state)
|
| 입력 데이터: tensor([[[1., 0., 0., 0.], [0., 1., 0., 0.], [0., 0., 1., 0.], [0., 0., 1., 0.], [0., 0., 0., 1.]], [[0., 1., 0., 0.], [0., 0., 0., 1.], [0., 0., 1., 0.], [0., 0., 1., 0.], [0., 0., 1., 0.]], [[0., 0., 1., 0.], [0., 0., 1., 0.], [0., 1., 0., 0.], [0., 1., 0., 0.], [0., 0., 1., 0.]]]) 출력 데이터: tensor([[[-0.5207, 0.9362], [-0.6398, 0.7532], [-0.5574, 0.8718], [-0.5574, 0.8718], [-0.1133, 0.7588]], [[-0.9055, 0.8389], [-0.6818, 0.8142], [-0.8767, 0.9132], [-0.8767, 0.9132], [-0.7872, 0.9210]], [[-0.9112, 0.8984], [-0.8855, 0.9052], [-0.9334, 0.8133], [-0.9334, 0.8133], [-0.9070, 0.9083]]], grad_fn=<StackBackward0>) 은닉 상태: tensor([[[-0.9112, 0.8984], [-0.8855, 0.9052], [-0.9334, 0.8133], [-0.9334, 0.8133], [-0.9070, 0.9083]]], grad_fn=<StackBackward0>) |
◼ test를 사용하여 고유한 문자 집합을 만들기
각 문자를 인덱스로 매핑하는 사전을 생성하기
이를 기반으로 입력 벡터와 은닉 상태 벡터의 크기를 설정
|
test = 'hello! world' string_set = list(set(test))
print(string_set)
string_dic = {c: i for i, c in enumerate(string_set)}
print(string_dic)
input_size = len(string_dic)
print(input_size)
hidden_size = len(string_dic)
print(hidden_size)
|
| ['!', 'l', 'd', 'e', 'o', 'r', 'w', 'h', ' '] ------------------------------------------------------------- {'!': 0, 'l': 1, 'd': 2, 'e': 3, 'o': 4, 'r': 5, 'w': 6, 'h': 7, ' ': 8} --------------------------------------------------------------- 9 9 |
◼ test라는 문자열을 string_dic이라는 사전에 기반하여 인덱스 리스트로 변환
test_idx 리스트를 x_data로 변환
|
test_idx = [string_dic[c] for c in test]
print(test_idx)
x_data = [test_idx[:]]
print(x_data)
|
| [7, 3, 1, 1, 4, 0, 8, 6, 4, 5, 1, 2] ---------------------------------------------- [[7, 3, 1, 1, 4, 0, 8, 6, 4, 5, 1, 2]] |
◼' x_data'리스트의 각 요소를 one-hot 인코딩 형식으로 변환하여 'x_one_hot '리스트를 만들기
|
x_one_hot = [np.eye(input_size)[x] for x in x_data]
print(x_one_hot)
|
| [array([[0., 0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 1.], [0., 0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 1., 0., 0., 0., 0., 0., 0.]])] |
◼ test_idx 리스트를 y_data로 복사하기
|
y_data = [test_idx[:]]
print(y_data)
|
| [[7, 3, 1, 1, 4, 0, 8, 6, 4, 5, 1, 2]] |
◼ RNN 모델을 학습시키기
|
X = torch.FloatTensor(x_one_hot)
y = torch.LongTensor(y_data)
rnn = RNN(input_size, hidden_size)
loss_fun = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(rnn.parameters(), lr = 0.1)
# outputs, state = rnn(X)
# loss: x, predition: x(idx), predition_str: x(str)
for i in range(100):
optimizer.zero_grad()
outputs, state = rnn(X)
# (배치사이즈, 시퀀스길이, 히든사이즈)
# outputs: (1, 12, 12) -> (12, 12)
# y: (1, 12) -> (12,)
loss = loss_fun(outputs.view(-1, input_size), y.view(-1))
loss.backward()
optimizer.step()
result = outputs.data.numpy().argmax(axis=2)
result_str = ''.join([string_set[ch] for ch in np.squeeze(result)])
print(i, 'loss: ', loss)
print('prediction: ', result, ' prediction_str: ', result_str)
|
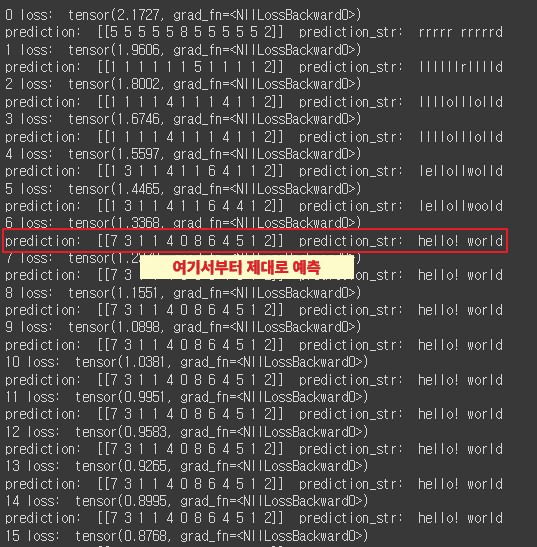 |
◼ RNN의 단점
: 입력과 출력이 고정
: 기울기 소실
: 단점을 극복하기 위해 RNN의 발전 형태인 LSTM과 GRU를 사용(문제를 완벽히 해결하지 못함)
'AI > 자연어처리' 카테고리의 다른 글
| 10. CNN Text Classification (0) | 2024.07.02 |
|---|---|
| 09. CBOW Text Classification (0) | 2024.07.01 |
| 07. 워드 임베딩 시각화 (0) | 2024.06.27 |
| 06. 자연어처리 - 워드 임베딩 (0) | 2024.06.25 |
| 05. 자연어처리 - 임베딩 실습 (0) | 2024.06.25 |



