SMALL
1. CNN Text Classification
- 참고 사이트: https://wikidocs.net/book/2155
◼ import
|
import urllib.request
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from copy import deepcopy
from torch.utils.data import Dataset, DataLoader
from tqdm.auto import tqdm
|
◼ 훈련 및 검증 데이터 불러오기
|
train_valid_dataset = pd.read_table('ratings_train.txt')
test_dataset = pd.read_table('ratings_test.txt')
|
◼ 데이터셋에 포함된 항목의 개수 출력
|
print(f'train_dataset : {len(train_dataset)}')
print(f'train_valid_dataset : {len(train_valid_dataset)}')
|
| train_dataset : 50000 train_valid_dataset : 150000 |
◼ 데이터 확인
|
train_valid_dataset.head()
|
◼ 데이터프레임을 무작위로 섞기
|
train_valid_dataset = train_valid_dataset.sample(frac=1.)
train_valid_dataset.head()
|
|
◼ train_valid_dataset | 훈련 데이터셋(80%) 검증 데이터셋(20%)
|
train_ratio = 0.8 n_train = int(len(train_valid_dataset) * train_ratio)
train_df = train_valid_dataset[:n_train]
valid_df = train_valid_dataset[n_train:]
print(f'train samples : {len(train_df)}')
print(f'valid samples : {len(valid_df)}')
print(f'test samples: {len(valid_df)}')
|
| train samples : 120000 valid samples : 30000 test samples: 30000 |
◼ 훈련 / 검증 / 테스트 데이터셋 | 10%씩 무작위로 샘플링
|
# 1/10으로 샘플링
train_df = train_df.sample(frac=0.1)
valid_df = valid_df.sample(frac=0.1)
test_df = test_df.sample(frac=0.1)
print(f'train samples : {len(train_df)}')
print(f'valid samples : {len(valid_df)}')
print(f'test samples: {len(test_df)}')
|
| train samples : 12000 valid samples : 3000 test samples: 5000 |
◼ <클래스 : NSMCDataset > 훈련, 검증 및 테스트 데이터셋을 생성
|
class NSMCDataset(Dataset):
def __init__(self, data_df, tokenizer=None):
self.data_df = data_df
self.tokenizer = tokenizer
def __len__(self):
return len(self.data_df)
# doc, label, doc_ids,
def __getitem__(self, idx):
sample_raw = self.data_df.iloc[idx]
sample = {}
sample['doc'] = str(sample_raw['document'])
sample['label'] = int(sample_raw['label'])
if self.tokenizer is not None:
sample['doc_ids'] = self.tokenizer(sample['doc'])
return sample
train_dataset = NSMCDataset(data_df=train_df, tokenizer=tokenizer)
valid_dataset = NSMCDataset(data_df=valid_df, tokenizer=tokenizer)
test_dataset = NSMCDataset(data_df=test_df, tokenizer=tokenizer)
|
데이터셋 길이 반환
샘플 반환
|
◼ 데이터셋 생성(훈련/검증/테스트)
|
train_dataset = NSMCDataset(data_df=train_df, tokenizer=tokenizer)
valid_dataset = NSMCDataset(data_df=valid_df, tokenizer=tokenizer)
test_dataset = NSMCDataset(data_df=test_df, tokenizer=tokenizer)
|
|
◼ 문서 / 레이블 / 토큰화된 문서 ID (토크나이저가 주어진 경우) 출력
|
print(train_dataset[0])
|
| { 'doc': '기덕이의 쓰레기 시리즈', 'label': 0, 'doc_ids': [1, 47, 397, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] } |
| 이 코드는 train_dataset의 첫 번째 샘플을 출력합니다. train_dataset은 NSMCDataset 클래스의 인스턴스이므로, train_dataset[0]은 NSMCDataset 클래스의 __getitem__ 메서드를 호출하여 첫 번째 샘플을 반환합니다. __getitem__ 메서드의 동작
|
◼ < 함수: collate_fn > 여러 샘플을 하나의 배치(batch)로 병합
|
def collate_fn(batch):
keys = [key for key in batch[0].keys()]
data = {key: [] for key in keys}
for item in batch:
for key in keys:
data[key].append(item[key])
return data
|
◼ DataLoader | 훈련 / 검증 / 테스트 데이터셋을 배치로 로드
|
train_dataloader = DataLoader(
train_dataset,
batch_size=128,
collate_fn=collate_fn,
shuffle=True
)
valid_dataloader = DataLoader(
valid_dataset,
batch_size=128,
collate_fn=collate_fn,
shuffle=False
)
test_dataloader = DataLoader(
test_dataset,
batch_size=128,
collate_fn=collate_fn,
shuffle=False
)
|
|
◼ 문서 / 레이블 / 토큰화된 문서 ID (토크나이저가 주어진 경우) 출력
|
sample = next(iter(test_dataloader))
sample.keys() # dict_keys(['doc','label','doc_ids])
sample['doc'][3] # 정말 재미지게 오랫동안 보게되는 드라마
print(sample['doc_ids'][3]) # [4, 17366, 2223, 2798, 52, 0 ... 0 ]
|
|
2. CNN Model
- N-gram 언어 모델(N-gram Language Model): https://wikidocs.net/21692
03-03 N-gram 언어 모델(N-gram Language Model)
n-gram 언어 모델은 여전히 카운트에 기반한 통계적 접근을 사용하고 있으므로 SLM의 일종입니다. 다만, 앞서 배운 언어 모델과는 달리 이전에 등장한 모든 단어를 고려하는 것…
wikidocs.net
◼ < 클래스 : SentenceCNN >
합성곱 신경망(Convolutional Neural Network, CNN)을 활용하여 문장을 처리하는 모델
|
class SentenceCNN(nn.Module):
def __init__(self, vocab_size, embed_dim, word_win_size=[3, 5, 7]):
super().__init__()
self.vocab_size = vocab_size
self.embed_dim = embed_dim
self.word_win_size = word_win_size
self.conv_list = nn.ModuleList(
[nn.Conv2d(1, 1, kernel_size=(w, embed_dim)) for w in self.word_win_size]
)
self.embeddings = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.output_dim = len(self.word_win_size)
def forward(self, X):
batch_size, seq_len = X.size()
X = self.embeddings(X) # batch_size * seq_len * embed_dim
X = X.view(batch_size, 1, seq_len, self.embed_dim) # batch_size * channel(1) * seq_len(H) * embed_dim(W)
C = [F.relu(conv(X)) for conv in self.conv_list]
C_hat = torch.stack([F.max_pool2d(
c, c.size()[2:]).squeeze() for c in C], dim=1)
return C_hat
|
- 주석
더보기
|
class SentenceCNN(nn.Module):
def __init__(self, vocab_size, embed_dim, word_win_size=[3, 5, 7]):
super().__init__()
self.vocab_size = vocab_size # 어휘 사전 크기
self.embed_dim = embed_dim # 임베딩 차원
self.word_win_size = word_win_size # 단어 윈도우 크기 리스트
# 각 단어 윈도우 크기에 대해 1개의 입력 채널, 1개의 출력 채널,
주어진 임베딩 차원 크기의 커널을 가지는 Conv2d 레이어를 생성 self.conv_list = nn.ModuleList(
[nn.Conv2d(1, 1, kernel_size=(w, embed_dim)) for w in self.word_win_size]
)
self.embeddings = nn.Embedding(vocab_size, embed_dim, padding_idx=0) # 임베딩 레이어 생성
self.output_dim = len(self.word_win_size) # 출력 차원 설정 (단어 윈도우 크기의 개수와 동일)
def forward(self, X):
batch_size, seq_len = X.size() # 입력 텐서의 크기를 가져옴
X = self.embeddings(X) # 입력을 임베딩 레이어를 통해 임베딩 벡터로 변환
X = X.view(batch_size, 1, seq_len, self.embed_dim) # Conv2d에 입력하기 위해 차원을 재구성 (batch_size * 1 * seq_len * embed_dim)
# 각 단어 윈도우 크기에 대해 Conv2d 레이어를 통과시키고 활성화 함수 ReLU를 적용하여 출력을 계산
C = [F.relu(conv(X)) for conv in self.conv_list]
# 각 Conv2d 레이어의 출력에서 최대 풀링을 적용하여 최대 풀링 값들을 스택으로 쌓음
C_hat = torch.stack([F.max_pool2d(c, c.size()[2:]).squeeze() for c in C], dim=1)
return C_hat
|
◼ < 클래스 : Classifier >
|
class Classifier(nn.Module):
def __init__(self, sr_model, output_dim, vocab_size, embed_dim, **kwargs):
super().__init__()
self.sr_model = sr_model(vocab_size=vocab_size, embed_dim=embed_dim, **kwargs)
self.input_dim = self.sr_model.output_dim
self.output_dim = output_dim
self.fc = nn.Linear(self.input_dim, self.output_dim)
def forward(self, x):
return self.fc(self.sr_model(x))
|
- 주석
더보기
|
class Classifier(nn.Module):
def __init__(self, sr_model, output_dim, vocab_size, embed_dim, **kwargs):
super().__init__()
# sr_model은 Sentence Representation Model로, 여기서는 CBOW나 SentenceCNN 등이 올 수 있습니다.
self.sr_model = sr_model(vocab_size=vocab_size, embed_dim=embed_dim, **kwargs)
self.input_dim = self.sr_model.output_dim # 입력 차원은 sr_model의 출력 차원과 동일하게 설정
self.output_dim = output_dim # 출력 차원 설정 (클래스 수)
self.fc = nn.Linear(self.input_dim, self.output_dim) # 완전 연결 레이어 정의
def forward(self, x):
# x는 입력 데이터입니다. sr_model을 통해 문장 표현을 추출하고, 이를 완전 연결 레이어에 통과시켜 예측을 수행합니다.
sentence_representation = self.sr_model(x) # sr_model을 사용하여 문장 표현을 추출
output = self.fc(sentence_representation) # 추출된 문장 표현을 완전 연결 레이어에 입력하여 예측값 계산
return output
|
◼ CNN 모델을 사용하여 단어 임베딩을 구성하고, 이를 기반으로 분류를 수행
|
model= Classifier(sr_model=CBOW, output_dim=2, vocab_size=len(vocabs), embed_dim=16)
model.sr_model.embedding.weight[0]
|
| tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], grad_fn=<SelectBackward0>) |
|
◼ CUDA 사용 가능 여부를 확인, 가능한 경우 모델을 GPU로 이동
|
use_cuda = True and torch.cuda.is_available()
if use_cuda:
model.cuda()
|
|
|
◼ 학습에 필요한 최적화 함수와 손실 함수를 설정
Adam 최적화 알고리즘은 모델 파라미터를 업데이트,
CrossEntropyLoss는 모델의 출력과 실제 레이블 간의 손실을 계산, 이를 최소화하는 방향으로 학습이 진행
|
optimizer = optim.Adam(params=model.parameters(), lr=0.01)
calc_loss = nn.CrossEntropyLoss()
|
|
|
◼ 모델을 학습 / 검증 | 최적의 모델을 선택하는 과정
학습 중에는 훈련 데이터셋을 사용하여 모델을 업데이트,
검증 데이터셋을 사용하여 모델의 성능을 평가
|
n_epoch = 10
global_i = 0
valid_loss_history = []
train_loss_history = []
best_model = None
best_epoch_i = None
min_valid_loss = 9e+9
|
|
|
for epoch_i in range(n_epoch): model.train()
|
|
|
for batch in train_dataloader: optimizer.zero_grad()
X = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X)
loss = calc_loss(y_pred, y)
if global_i % 1000 == 0:
print(f'i: {global_i}, epoch: {epoch_i}, loss: {loss.item()}')
train_loss_history.append((global_i, loss.item()))
loss.backward()
optimizer.step()
global_i += 1
|
|
|
model.eval() valid_loss_list = []
for batch in valid_dataloader:
X = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X)
loss = calc_loss(y_pred, y)
valid_loss_list.append(loss.item())
valid_loss_mean = np.mean(valid_loss_list)
valid_loss_history.append((global_i, valid_loss_mean.item()))
|
|
|
if valid_loss_mean < min_valid_loss: min_valid_loss = valid_loss_mean
best_epoch_i = epoch_i
best_model = deepcopy(model)
|
|
|
if epoch_i % 2 == 0: print("*"*30)
print(f'valid_loss_mean: {valid_loss_mean}')
print("*"*30)
|
|
|
print(f'best_epoch: {best_epoch_i}') |
|
i: 0, epoch: 0, loss: 0.7246869206428528 ****************************** valid_loss_mean: 0.4771331803912812 ****************************** i: 1000, epoch: 1, loss: 0.4654802680015564 i: 2000, epoch: 2, loss: 0.2945984899997711 ****************************** valid_loss_mean: 0.48677011642684326 ****************************** i: 3000, epoch: 4, loss: 0.2991761267185211 ****************************** valid_loss_mean: 0.623231903194113 ****************************** i: 4000, epoch: 5, loss: 0.18949878215789795 i: 5000, epoch: 6, loss: 0.16362766921520233 ****************************** valid_loss_mean: 0.7651025318401925 ****************************** i: 6000, epoch: 8, loss: 0.19161175191402435 ****************************** valid_loss_mean: 0.9227979858504965 ****************************** i: 7000, epoch: 9, loss: 0.13517844676971436 best_epoch: 1 |
|
- 전체코드
더보기
|
n_epoch = 10 # 총 에포크 수
global_i = 0 # 전체 반복 횟수
valid_loss_history = [] # 검증 손실 기록 리스트
train_loss_history = [] # 훈련 손실 기록 리스트
best_model = None # 최적의 모델을 저장할 변수
best_epoch_i = None # 최적의 에포크 인덱스를 저장할 변수
min_valid_loss = 9e+9 # 초기 최소 검증 손실 설정
# 에포크 반복
for epoch_i in range(n_epoch):
model.train() # 모델을 학습 모드로 설정
# 훈련 데이터셋 반복
for batch in train_dataloader:
optimizer.zero_grad() # optimizer의 gradient를 초기화
X = torch.tensor(batch['doc_ids']) # 입력 데이터
y = torch.tensor(batch['label']) # 레이블
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X) # 모델에 입력 데이터를 전달하여 예측값을 계산
loss = calc_loss(y_pred, y) # 손실 계산
# 매 1000번째 반복마다 손실 출력
if global_i % 1000 == 0:
print(f'i: {global_i}, epoch: {epoch_i}, loss: {loss.item()}')
train_loss_history.append((global_i, loss.item())) # 훈련 손실 기록
loss.backward() # 역전파를 통해 gradient 계산
optimizer.step() # optimizer를 사용하여 모델 파라미터 업데이트
global_i += 1 # 전체 반복 횟수 증가
model.eval() # 모델을 평가 모드로 설정
valid_loss_list = [] # 검증 손실을 저장할 리스트 초기화
# 검증 데이터셋 반복
for batch in valid_dataloader:
X = torch.tensor(batch['doc_ids']) # 입력 데이터
y = torch.tensor(batch['label']) # 레이블
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X) # 모델에 입력 데이터를 전달하여 예측값을 계산
loss = calc_loss(y_pred, y) # 손실 계산
valid_loss_list.append(loss.item()) # 검증 손실 기록
valid_loss_mean = np.mean(valid_loss_list) # 검증 손실의 평균 계산
valid_loss_history.append((global_i, valid_loss_mean.item())) # 검증 손실 기록
# 현재 검증 손실이 최소 검증 손실보다 작으면 최적 모델을 업데이트
if valid_loss_mean < min_valid_loss:
min_valid_loss = valid_loss_mean # 최소 검증 손실 업데이트
best_epoch_i = epoch_i # 최적의 에포크 인덱스 업데이트
best_model = deepcopy(model) # 최적의 모델을 deepcopy하여 저장
# 매 두 번째 에포크마다 현재 검증 손실을 출력
if epoch_i % 2 == 0:
print("*"*30)
print(f'valid_loss_mean: {valid_loss_mean}')
print("*"*30)
# 최적의 에포크 인덱스 출력
print(f'best_epoch: {best_epoch_i}')
|
◼ 훈련과 검증 손실의 추이를 시각화
|
def calc_moving_average(arr, win_size=100):
new_arr = []
win = []
for i, val in enumerate(arr):
win.append(val)
if len(win) > win_size:
win.pop(0)
new_arr.append(np.mean(win))
return np.array(new_arr)
valid_loss_history = np.array(valid_loss_history)
train_loss_history = np.array(train_loss_history)
plt.figure(figsize=(12,8))
plt.plot(train_loss_history[:,0],
calc_moving_average(train_loss_history[:,1]), color='blue')
plt.plot(valid_loss_history[:,0],
valid_loss_history[:,1], color='red')
plt.xlabel("step")
plt.ylabel("loss")
|
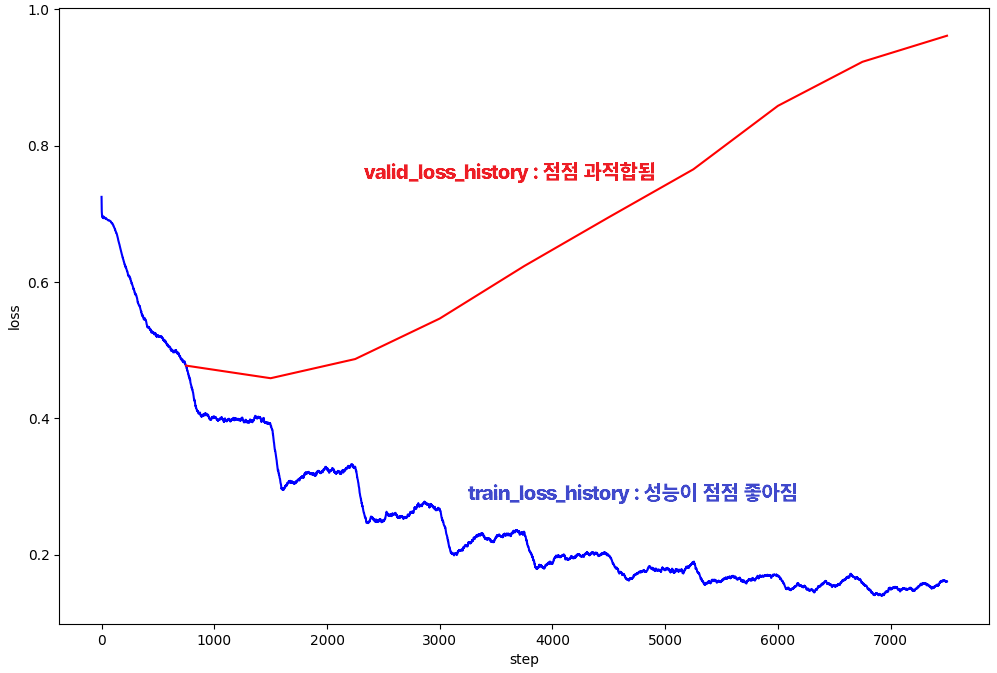 |
- 주석
더보기
|
def calc_moving_average(arr, win_size=100):
new_arr = [] # 이동 평균을 계산하여 저장할 리스트
win = [] # 이동 평균을 계산할 윈도우 리스트
for i, val in enumerate(arr):
win.append(val) # 현재 값을 윈도우에 추가
if len(win) > win_size:
win.pop(0) # 윈도우 크기를 유지하기 위해 가장 오래된 값 제거
new_arr.append(np.mean(win)) # 윈도우 내 값들의 평균을 계산하여 new_arr에 추가
return np.array(new_arr) # 계산된 이동 평균 배열 반환
valid_loss_history = np.array(valid_loss_history) # 검증 손실 기록을 NumPy 배열로 변환
train_loss_history = np.array(train_loss_history) # 훈련 손실 기록을 NumPy 배열로 변환
# 손실 추이를 시각화하는 그래프 생성
plt.figure(figsize=(12, 8)) # 그래프 크기 설정
plt.plot(train_loss_history[:, 0], calc_moving_average(train_loss_history[:, 1]), color='blue') # 훈련 손실의 이동 평균을 파란색으로 플롯
plt.plot(valid_loss_history[:, 0], valid_loss_history[:, 1], color='red') # 검증 손실을 빨간색으로 플롯
plt.xlabel("step") # x축 레이블 설정
plt.ylabel("loss") # y축 레이블 설정
|
◼ 테스트 데이터셋에서 정확도를 계산
|
model = best_model # 최적의 모델을 선택하여 model 변수에 할당
model.eval() # 모델을 평가 모드로 설정 (드롭아웃, 배치 정규화 등의 동작이 평가 모드로 변경됨)
total = 0 # 전체 예측 수 초기화
correct = 0 # 정확하게 예측된 수 초기화
# 테스트 데이터셋의 각 배치에 대해 반복하면서 예측 정확도 계산
for batch in tqdm(test_dataloader, total=len(test_dataloader.dataset)//test_dataloader.batch_size):
X = torch.tensor(batch['doc_ids']) # 입력 데이터
y = torch.tensor(batch['label']) # 실제 레이블
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X) # 모델을 사용하여 예측값 계산
# 예측값과 실제 레이블을 비교하여 정확한 예측 수 계산
curr_correct = y_pred.argmax(dim=1) == y
total += len(curr_correct) # 현재 배치의 전체 예측 수를 누적
correct += sum(curr_correct) # 현재 배치에서 정확하게 예측된 수를 누적
# 전체 테스트 데이터셋에 대한 정확도 계산 및 출력
print(f'test accuracy: {correct/total}')
|
| 0.765250027179718 |
'AI > 자연어처리' 카테고리의 다른 글
| 12. 문장 임베딩 | Seq2Seq (1) | 2024.07.03 |
|---|---|
| 11. LSTM과 GRU (0) | 2024.07.02 |
| 09. CBOW Text Classification (0) | 2024.07.01 |
| 08. RNN 기초 (0) | 2024.06.27 |
| 07. 워드 임베딩 시각화 (0) | 2024.06.27 |



