1. 네이버 영화 리뷰 데이터 셋
- 총 20만개의 리뷰로 구성된 데이터로, 영화 리뷰를 긍/부정으로 분류하기 위해 만들어진 데이터셋
- 리뷰가 긍정인 경우1, 부정인 경우 0으로 표시한 레이블로 구성되어 있음
◼ 데이터 준비
- 설치
|
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
|
- import
|
import urllib.request
import pandas as pd
|
- git-hub에 올라가 있는 파일 가져오기
|
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt', filename='ratings_train.txt' )
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt', filename='ratings_test.txt' )
|
 |
- 학습 데이터를 데이터프레임으로 받아오기
|
train_dataset = pd.read_table('ratings_test.txt')
train_dataset
|
 |
◼ 데이터 전처리
- 결측치를 확인하고 결측치를 제거하기
|
train_dataset.replace('',float('NaN'),inplace=True)
train_dataset.isnull().values.any()
train_dataset=train_dataset.dropna().reset_index(drop=True)
len(train_dataset)
|
| 149995 |
- 열(document)을 기준으로 중복 데이터를 제거하기
|
train_dataset = train_dataset.drop_duplicates(['document']).reset_index(drop=True)
print(f'필터링된 데이터의 총 개수: {len(train_dataset)}')
|
| 필터링된 데이터의 총 개수: 146182 |
- 힌글이 아닌 문자를 포함하는 데이터를 제거하기 (단, ㅋㅋㅋ 제거하지 않음)
|
import re
train_dataset['document'] = train_dataset['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣]", " ", regex=True)
train_dataset
|
 |
- 너무 짧은 단어를 제거하기(한 글자 이하)
|
train_dataset['document'] = train_dataset['document'].apply(lambda x: ' '.join([token for token in x.split() if len(token) > 1]))
train_dataset
|
 |
- 전체 길이가 50자 이하이거나 전체 단어의 개수가 3개 이하인 데이터를 제거하기
|
train_dataset = train_dataset[train_dataset.document.apply(lambda x: len(str(x)) > 50 and len(str(x).split()) > 3)].reset_index(drop=True)
train_dataset
|
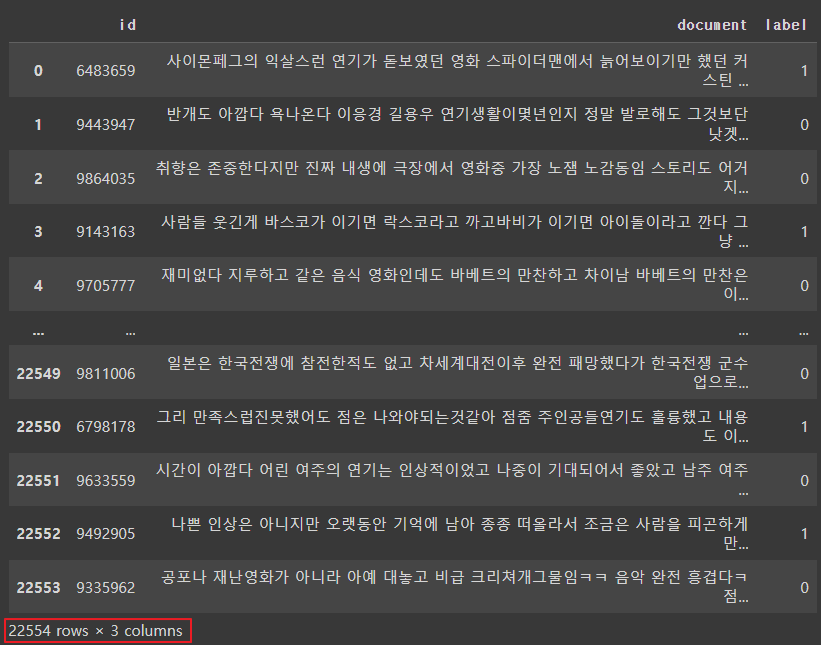 |
- 불용어를 확인하고 불용어 제거하기
|
! pip install konlpy
from konlpy.tag import Okt
stopwords = ['아', '휴', '아이구', '아이쿠', '아이고', '어', '나', '우리', '저희', '따라', '의해', '을', '를', '에', '의', '가', '으로', '로', '에게', '뿐이다', '의거하여', '근거하여', '입각하여', '기준으로', '예하면', '예를', '들면', '예를', '들자면', '저', '소인', '소생', '저희', '지말고', '하지마', '하지마라', '다른', '물론', '또한', '그리고', '비길수', '없다', '해서는', '안된다', '뿐만', '아니라', '만이', '아니다', '만은', '아니다', '막론하고', '관계없이', '그치지', '않다', '그러나', '그런데', '하지만', '든간에', '논하지', '않다', '따지지', '않다', '설사', '비록', '더라도', '아니면', '만', '못하다', '하는', '편이', '낫다', '불문하고', '향하여', '향해서', '향하다', '쪽으로', '틈타', '이용하여', '타다', '오르다', '제외하고', '이', '외에', '이', '밖에', '하여야', '비로소', '한다면', '몰라도', '외에도', '이곳', '여기', '부터', '기점으로', '따라서', '할', '생각이다', '하려고하다', '이리하여', '그리하여', '그렇게', '함으로써', '하지만', '일때', '할때', '앞에서', '중에서', '보는데서', '으로써', '로써', '까지', '해야한다', '일것이다', '반드시', '할줄알다', '할수있다', '할수있어', '임에', '틀림없다', '한다면', '등', '등등', '제', '겨우', '단지', '다만', '할뿐', '딩동', '댕그', '대해서', '대하여', '대하면', '훨씬', '얼마나', '얼마만큼', '얼마큼']
train_dataset = list(train_dataset['document'])
|
- 모든 형태소를 tokenized_data에 저장. 단 원형으로 표기
|
okt = Okt()
tokenized_data = []
for sentence in train_dataset:
tokenized_sentence = okt.morphs(sentence, stem=True)
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords]
tokenized_data.append(stopwords_removed_sentence)
print(tokenized_data[0])
|
| ['사이', '몬페', '그', '익살스럽다', '연기', '돋보이다', '영화', '스파이더맨', '에서', '늙다', '보이다', '하다', '커스틴', '던스트', '너무나도', '이쁘다', '보이다'] |
- 리뷰의 최대 길이와 리뷰의 평균 길이를 출력하기
|
print('리뷰의 최대 길이', max(len(review) for review in tokenized_data))
print('리뷰의 평균 길이', sum(map(len, tokenized_data))/len(tokenized_data))
|
| 리뷰의 최대 길이 73 리뷰의 평균 길이 27.925290414117228 |
2. 워드 임베딩 구축
◼ gensim 라이브러리를 사용하여 Word2Vec 모델을 학습
( 학습된 모델에서 임베딩 행렬의 크기를 출력 )
|
from gensim.models import Word2Vec
enbedding_dim = 100
# sg: 0(CBOW), 1(Skip-gram)
model = Word2Vec(
sentences = tokenized_data,
vector_size = enbedding_dim,
window = 5,
min_count = 5,
workers = 4,
sg = 0,
)
# 임베딩 행렬의 크기
model.wv.vectors.shape
|
| (8518, 100) |
◼ Word2Vec 모델에서 학습된 단어 벡터를 가져와서 사용하기
|
word_vectors = model.wv
vocabs = list(word_vectors.index_to_key)
print(vocabs[:20])
|
| ['하다', '영화', '보다', '도', '들', '는', '은', '있다', '이다', '한', '같다', '좋다', '너무', '되다', '적', '에서', '정말', '과', '진짜', '연기'] |
|
◼ 비슷한 단어 출력
|
for sim_word in model.wv.most_similar('영화'):
print(sim_word)
for sim_word in model.wv.most_similar('좋다'):
print(sim_word)
|
| ('영화로', 0.7965032458305359) ('애니', 0.7777377367019653) ('실화', 0.7423218488693237) ('애니메이션', 0.7393093705177307) ('공포영화', 0.7195255756378174) ('수작', 0.7077005505561829) ('다큐', 0.706235408782959) ('장르', 0.6991435885429382) ('졸작', 0.6942315697669983) ('명작', 0.6928736567497253) --------------------------------------------- ('훌륭하다', 0.7986271977424622) ('예쁘다', 0.7874795794487) ('많이', 0.7848160862922668) ('멋지다', 0.7816267609596252) ('신선하다', 0.7701767086982727) ('사랑스럽다', 0.7624828815460205) ('괜찮다', 0.7616109251976013) ('대단하다', 0.7428885102272034) ('유아인', 0.7396495342254639) ('수영', 0.7395205497741699) |
3. 워드 임베딩 시각화
◼ 글씨체 넣기
|
import matplotlib.font_manager
import matplotlib.pyplot as plt
font_list = matplotlib.font_manager.findSystemFonts(fontpaths=None, fontext='ttf')
[matplotlib.font_manager.FontProperties(fname=font).get_name() for font in font_list if 'Nanum' in font]
|
◼ Matplotlib을 사용하여 단어 벡터 리스트에서 단어 벡터를 추출
|
plt.rc('font', family = 'NanumBarunGothic')
word_vector_list = [word_vectors[word] for word in vocabs]
word_vector_list[0]
|
| array([-1.9381499e-01, -4.1600460e-01, 9.7493243e-01, 1.2037897e+00, -5.3793442e-01, -8.1196767e-01, 4.8179775e-01, 7.7839744e-01, -8.7139791e-01, -1.4249954e-01, -3.4433335e-01, 8.1975532e-01, -7.5461555e-01, 4.7540924e-01, 3.7810212e-01, 1.2024163e-01, 4.9804041e-01, 1.6904233e-02, -7.5146669e-01, -7.4627143e-01, 1.1594934e+00, 9.0792847e-01, 1.3075854e+00, -2.3236538e-01, 7.3629230e-01, 6.4110452e-01, -9.7711064e-02, 6.4268851e-01, -1.5924544e+00, -2.9106671e-01, 2.3725238e-01, 3.6944515e-01, 4.1880410e-02, -3.7169051e-01, -1.7793979e-01, -2.3869032e-01, 7.4778670e-03, -8.3802915e-01, -9.1370374e-01, 2.5593418e-01, -9.6287352e-01, -2.3086920e-01, -7.7384102e-01, 2.3146048e-01, 3.4021482e-01, 2.0604472e-04, -6.4717674e-01, -1.1628787e-02, 1.1950109e+00, 2.8277171e-01, -5.5411488e-01, 8.4798664e-01, -1.6041585e+00, -3.3900287e-02, 9.4806898e-01, -2.7566156e-01, 6.3661528e-01, -3.8892531e-01, -1.2240679e+00, 3.3968832e-02, 3.2375928e-02, 4.5298886e-01, 2.1698034e-01, -5.1100832e-01, 2.9746948e-02, 4.7515121e-01, -4.0168327e-01, -4.2111692e-01, -5.6812203e-01, 4.7299665e-01, -4.2577378e-02, 7.3512268e-01, -1.0462348e+00, -7.8099775e-01, 9.0860772e-01, 1.0109191e+00, 5.6336063e-01, 7.9223849e-02, -4.3722951e-01, -2.6502195e-01, 6.2837178e-01, -4.2854306e-01, -1.2790999e-01, 7.8651458e-01, -8.9481264e-02, 1.6315395e-01, 5.8857971e-01, 3.9358994e-01, 3.4204671e-01, 4.9580792e-01, 9.9583191e-01, 8.4775341e-01, 4.9439617e-02, 4.2350531e-02, 6.2765265e-01, 1.8409020e-01, 1.3223439e-01, -3.4866560e-01, 5.5834359e-01, -3.2748231e-01], dtype=float32) |
◼ PCA : 차원축소방식, 자주 이용되는 방식이긴 하지만 변별력을 해친다는 단점
PCA를 개선한 방법이 t-SNE 차원축소 방식
|
import numpy as np
from sklearn.manifold import TSNE
# TSNE 객체를 생성
- n_components는 축소할 차원의 수를 의미합니다 (여기서는 2차원으로 축소). - learning_rate는 학습률을 의미하며, 'auto'로 설정하면 자동으로 결정됩니다.
- init은 초기화 방법을 지정합니다 (여기서는 'random'으로 설정).
tsne = TSNE(n_components=2, learning_rate = 'auto', init = 'random')
# word_vector_list를 numpy 배열로 변환한 후 TSNE 모델에 fitting 및 변환을 수행
transformed = tsne.fit_transform(np.array(word_vector_list))
# 변환된 결과에서 x축과 y축에 해당하는 값들을 추출
x_axis_tsne = transformed[:, 0]
y_axis_tsne = transformed[:, 1]
# 변환된 값들을 출력합니다.
print(x_axis_tsne)
print(y_axis_tsne)
|
| [ 72.80775 53.888332 39.27514 ... -14.821895 -71.93072 -42.643425] [10.166324 41.57702 48.48687 ... -8.985083 -3.952842 4.07729 ] |
◼ matplotlib을 사용하여 t-SNE를 통해 차원 축소된 단어 벡터를 시각화
|
def plot_tsne_graph(vocabs, x_asix, y_asix):
plt.figure(figsize=(30, 30))
plt.scatter(x_asix, y_asix, marker = 'o')
for i, v in enumerate(vocabs):
plt.annotate(v, xy=(x_asix[i], y_asix[i]))
plot_tsne_graph(vocabs, x_axis_tsne, y_axis_tsne)
|
 |
4. TSNE 고도화
- 파이썬에서 제공하는 interactive visualization library 인 [Bokey]를 사용하여 시각화
- Bokey 사이트: https://docs.bokeh.org/en/latest/
◼ t-SNE를 통해 차원 축소된 결과를 pandas의 DataFrame으로 변환하여 출력
|
tsne_df = pd.DataFrame(transformed, columns = ['x_coord', 'y_coord'])
tsne_df['word'] = vocabs
tsne_df
|
 |
◼ Bokeh 라이브러리를 사용하여 t-SNE로 차원 축소된 단어 벡터를 시각화(1)
|
from bokeh.plotting import figure, show, output_notebook
from bokeh.models import HoverTool, ColumnDataSource
tsne_df = pd.DataFrame(transformed, columns = ['x_coord', 'y_coord'])
output_notebook()
plot_data = ColumnDataSource(tsne_df)
tsne_plot = figure(title='t-SNE Word Embeddings',
width = 800,
height = 800,
active_scroll='wheel_zoom'
)
tsne_plot.add_tools( HoverTool(tooltips = '@word') )
tsne_plot.circle(
'x_coord', 'y_coord', source=plot_data,
color='red', line_alpha=0.2, fill_alpha=0.1,
size=10, hover_line_color='orange'
)
tsne_plot.xaxis.visible = False
tsne_plot.yaxis.visible = False
tsne_plot.grid.grid_line_color = None
tsne_plot.outline_line_color = None
show(tsne_plot);
|
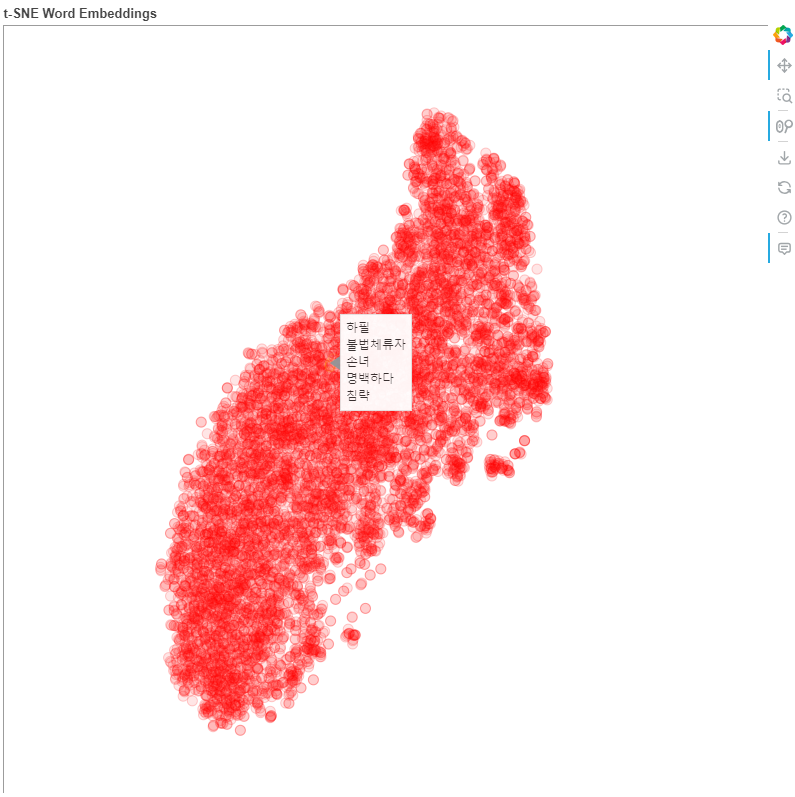 |
◼ Bokeh 라이브러리를 사용하여 t-SNE로 차원 축소된 단어 벡터를 시각화
|
import numpy as np
from bokeh.plotting import figure, show,output_notebook
import matplotlib.pyplot as plt
tsne_df = pd.DataFrame(transformed, columns=['x_coord', 'y_coord'])
tsne_df['vocabs'] = vocabs
plt.rc('font', family='NanumGothic')
output_notebook(resources=INLINE)
N = 8518
radii = np.random.random(size=N) * 1.5
x = tsne_df['x_coord']
y = tsne_df['y_coord']
colors = np.array([(r, g, 150) for r, g in zip(50+2*x, 30+2*y)], dtype="uint8")
TOOLTIPS = [("vocabs", "@vocabs")]
TOOLS="hover,crosshair,pan,wheel_zoom,zoom_in,zoom_out,box_zoom,undo,redo,reset,tap,save,box_select,poly_select,lasso_select,examine,help"
source = ColumnDataSource(data=dict(x=x, y=y, radii=radii, colors=colors, vocabs=tsne_df['vocabs']))
p = figure(tools=TOOLS , tooltips=TOOLTIPS)
p.circle('x', 'y', radius='radii', source=source,
fill_color='colors', fill_alpha=0.6,
line_color=None)
show(p,notebook_handle=True)
|
 |
'AI > 자연어처리' 카테고리의 다른 글
| 09. CBOW Text Classification (0) | 2024.07.01 |
|---|---|
| 08. RNN 기초 (0) | 2024.06.27 |
| 06. 자연어처리 - 워드 임베딩 (6) | 2024.06.25 |
| 05. 자연어처리 - 임베딩 실습 (0) | 2024.06.25 |
| 04. 자연어처리 - 임베딩 (1) | 2024.06.25 |



