1. Rent 데이터셋
- 집월세 매물정보
- 출처: 캐글
- 작업파일
- import
import numpy as np
import pandas as pd
import seaborn as sns
- 파일 가져오기
rent_df = pd.read_csv('/content/drive/MyDrive/1. KDT/6. 머신러닝 딥러닝/데이터/rent.csv')
rent_df
  |
- 정보보기
rent_df.info()
 |
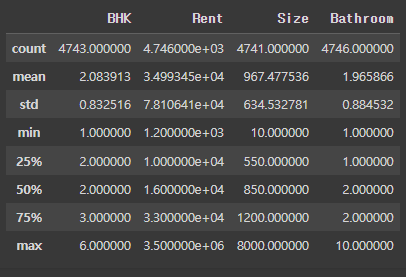
- 통계량, 평균치 보기
# describe() 함수는 수치 기준으로 나온 데이터들을 테이블로 변환
rent_df.describe()
 |
- 소수점 둘째 자리까지 반올림하여 보기
round(rent_df.describe(), 2)
 |
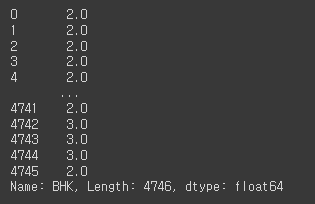
- Bed, hall, kitchen의 갯수
rent_df['BHK']
 |
- [BHK] 막대그래프로 보기
sns.displot(rent_df['BHK'])
 |
- [Rent] 가격이 몰려있음
sns.displot(rent_df['Rent'])
 |
- [Rent] 이상치 데이터 예측
rent_df['Rent'].sort_values()
 |
- [Rent] 편차가 심해서 박스권 밖으로 나가있음
sns.boxplot(y=rent_df['Rent'])
 |
- 반면, [BHK] 이상치 데이터가 없음
sns.boxplot(y=rent_df['BHK'])
 |
- null 값 데이터 확인
rent_df.isna().sum()
 |
- null 값 데이터 퍼센테이지로 확인 (적은 수치라 삭제하는 게 좋을 듯함)
rent_df.isna().mean()
 |
- BHK에 있는 결측치 데이터를 삭제
# BHK에 있는 결측치 데이터를 삭제
rent_df.dropna(subset=['BHK'])
 |
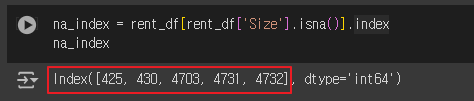
- 'Size' 열이 결측값인 행들을 반환
na_index = rent_df[rent_df['Size'].isna()].index
na_index
 |
- rent_df의 결측값 중앙값으로 채우고 확인
rent_df['Size'].fillna(rent_df['Size'].median()).loc[na_index]
 |
- 숫자형 열의 중앙값을 계산하여 fillna() 함수를 사용해 결측값 채우기
결측값의 비율
rent_df = rent_df.fillna(rent_df.median(numeric_only=True))
rent_df.isna().mean()
 |
2. 데이터 전처리
- 렌트비와 연관성 있는 데이터 보기
rent_df.info()
 |
- [ Floor ] 열 확인
# 종류가 너무 많음 , 숫자로 변환해야 할 필요성
rent_df['Floor'].value_counts()
 |
- [ Area Type ] 확인
# 카테고리가 3개, 원핫인코딩 가능
# Area Type은 텍스트 형태이기 때문에 모델에서 계산을 할 수 없음
# 라벨 인코딩을 통해 숫자로 변경
rent_df['Area Type'].value_counts()
 |
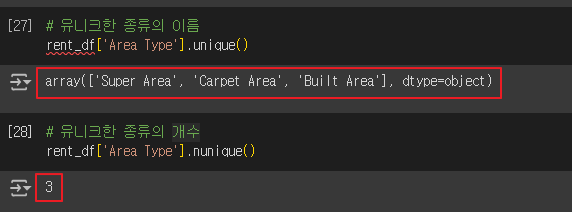
- 'Area Type' 열에 있는 고유한 값
# 유니크한 종류의 이름
rent_df['Area Type'].unique()
# 유니크한 종류의 개수
rent_df['Area Type'].nunique()
 |
- 원핫인코딩에서 제외할 데이터 확인 (값이 너무 많은 것은 제외)
# 각 열마다 유니크한 값 개수
for i in ['Floor', 'Area Type', 'Area Locality', 'City', 'Furnishing Status', 'Tenant Preferred', 'Point of Contact']:
print(i, rent_df[i].nunique())
 |
- 원핫인코딩에서 제외할 열 삭제
rent_df.drop(['Posted On', 'Floor', 'Area Locality', 'Tenant Preferred', 'Point of Contact'], axis=1, inplace=True)
rent_df.info()
 |
- 문자열 데이터 원핫인코딩 하기
rent_df = pd.get_dummies(rent_df, columns = ['Area Type', 'City', 'Furnishing Status'])
rent_df.head()
  |
- 학습용(train)과 테스트용(test) 세트로 데이터분할
X = rent_df.drop('Rent', axis=1) # 독립변수 (차원이 있음, 행렬형태)
y = rent_df['Rent'] # 종속변수(단일값)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
X_train.shape, X_test.shape
y_train.shape, y_test.shape
 |
3. 선형회귀(Linear Regression)
데이터를 통해 가장 잘 설명할 수 있는 직선으로 데이터를 분석하는 방법
단순 선형 회귀 분석( 단일 독립변수를 이용 )
다중 선형 회귀 분석( 다중 독립변수를 이용 )
🔴 단순 선형회귀 모델  |
🔻예시간단한 예시를 들어보겠습니다. 예를 들어, 집의 크기(X)와 가격(Y) 간의 관계를 선형회귀로 모델링하고자 한다면,다음과 같은 단순 선형회귀 모델을 사용할 수 있습니다:  이 모델을 사용하여 새로운 집의 크기에 대한 가격을 예측할 수 있습니다. 만약 우리가 집의 크기(X)와 가격(Y)의 관계를 모델링하는 경우를 생각해봅시다. 주어진 데이터에서 다음과 같은 선형 회귀식을 얻었다고 가정합시다.   |
🔵 다중 선형회귀 모델
  |
🔹예시간단한 예시를 들어보겠습니다.예를 들어, 집의 가격(Y)을 예측하기 위해 집의 크기(X1), 방의 개수(X2), 위치(X3) 등을 독립 변수로 사용하는 모델을 생각해봅시다.   |
- import
from sklearn.linear_model import LinearRegression
- 학습하기
lr = LinearRegression()
lr.fit(X_train, y_train)
 |
- 선형 회귀 모델(lr)을 사용하여
X_test 데이터를 기반으로 예측을 수행하고, 예측 결과를 pred 변수에 저장
pred = lr.predict(X_test)
pred
 |
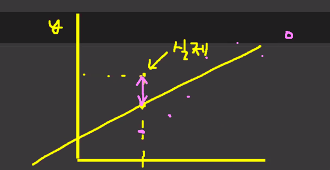
4. 평가지표 만들기
- MSE (Mean Squared Error)
- MAE (Mean Absolute Error)
- RMSE (Root Mean Squared Error)

|
  |
- 예측값, 실제값 설정
p = np.array([3,4,5]) # 예측값
act = np.array([1,2,3]) # 실제값
- MSE를 직접 구현
def my_mse(pred, actual):
return((pred - actual) ** 2).mean()
my_mse(p, act)
| 4.0 (차이값) |
|
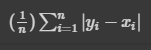 |
- MAE를 직접 구현
def my_mae(pred, actual):
return np.abs(pred - actual).mean()
my_mae(p, act)
| 2.0 |
|
 |
- RMSE를 직접 구현
def my_rmse(pred, actual):
return np.sqrt(my_mse(pred, actual))
my_rmse(p, act)
| 2.0 |
- scikit-learn 라이브러리를 사용
두 배열 사이의 평균 절대 오차(MAE, Mean Absolute Error)를 계산하기
from sklearn.metrics import mean_absolute_error, mean_squared_error
mean_absolute_error(p, act)
mean_squared_error(p, act)
mean_squared_error(p, act, squared=False) # RMSE
 |
- 데이터에 평가지표 적용하기
: 평균 절대 오차(MAE, Mean Absolute Error)를 계산
mean_squared_error(y_test, pred)
mean_absolute_error(y_test, pred)
mean_squared_error(y_test, pred, squared=False)
 |
- 오차값 줄이기 위해 전처리 바꿔보기
# 아웃라이어로 생각되는 데이터를 삭제
X_train.drop(1837, inplace=True)
y_train.drop(1837, inplace=True)
더보기
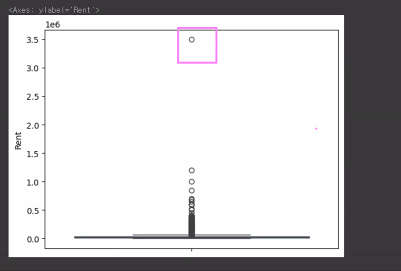

이상치 데이터 지워보기
- 다시 학습시키기
# 다시 학습시키기
lr.fit(X_train, y_train)
 |
- 테스트 세트(X_test)를 사용하여
예측된 값(pred)과 실제 타겟 값(y_test) 간의
평균 제곱근 오차(Root Mean Squared Error, RMSE)를 계산
pred= lr.predict(X_test)
mean_squared_error(y_test, pred, squared=False)
| 37731.275512059074 |
- 성능차이
# 1837 삭제전 : 37765.125980605386
# 1837 삭제후 : 37731.275512059074
# 성능 좋아짐 : - 3.850468546312186
5. LinearSVC - LinearRegression 차이?
- 분류 (Classification)
- 회귀 (Regression)
|
LinearSVC와 LinearRegression은 모두 선형 모델이지만,
각각의 목적과 사용 사례가 다릅니다. 여기서는 두 모델의 주요 차이점을 설명하겠습니다. LinearSVC (Linear Support Vector Classification)
LinearRegression
|
주요 차이점 요약
예를 들어, 이진 분류 문제에서는 LinearSVC를 사용하고, 연속적인 값 예측 문제에서는 LinearRegression을 사용하는 것이 적절합니다. |
'AI > 머신러닝' 카테고리의 다른 글
| 07. 로지스틱 회귀(Logistic Regression) | 인사자료 (0) | 2024.06.12 |
|---|---|
| 06. 의사결정 나무(Decision Tree) | 자전거 (0) | 2024.06.11 |
| 04. 데이터 전처리 | 타이타닉 (1) | 2024.06.10 |
| 03. SVC, accuracy_score | 아이리스 (1) | 2024.06.10 |
| 02. 사이킷런 (Scikit-learn) | LinearSVC (0) | 2024.06.10 |



