SMALL
1. 아이리스 데이터셋
- 데이터셋:특정한 작업을 위해 데이터를 관련성 있게 모아놓은 것
- 아이리스 데이터셋 : 머신러닝에서 분류 알고리즘을 학습하고 평가하는 데 자주 사용되는 예제 데이터셋
- 아이리스 데이터 찾기
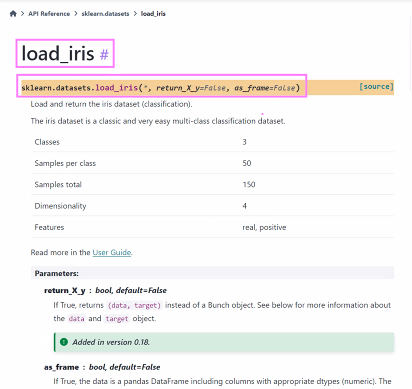
- 아이리스 데이터 import
: scikit-learn 라이브러리에서 load_iris 함수를 불러오기
from sklearn.datasets import load_iris
- load_iris 함수를 사용하여 아이리스 붓꽃 데이터셋을 로드한 후, 이를 iris 변수에 저장
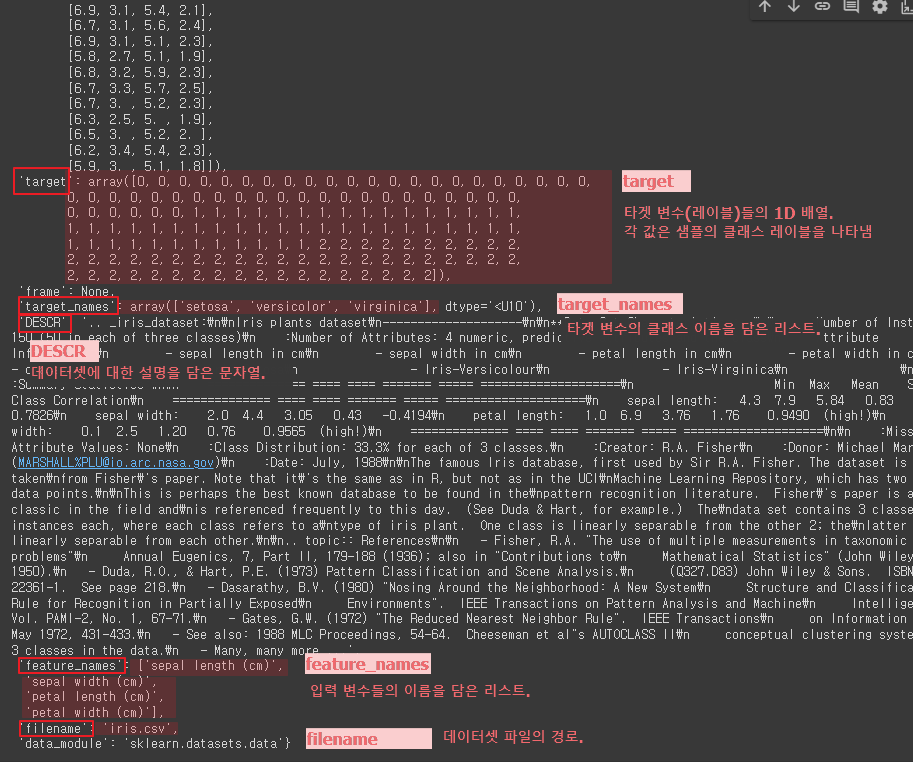
iris = load_iris() # 아이리스 붓꽃 데이터
iris
  |
|
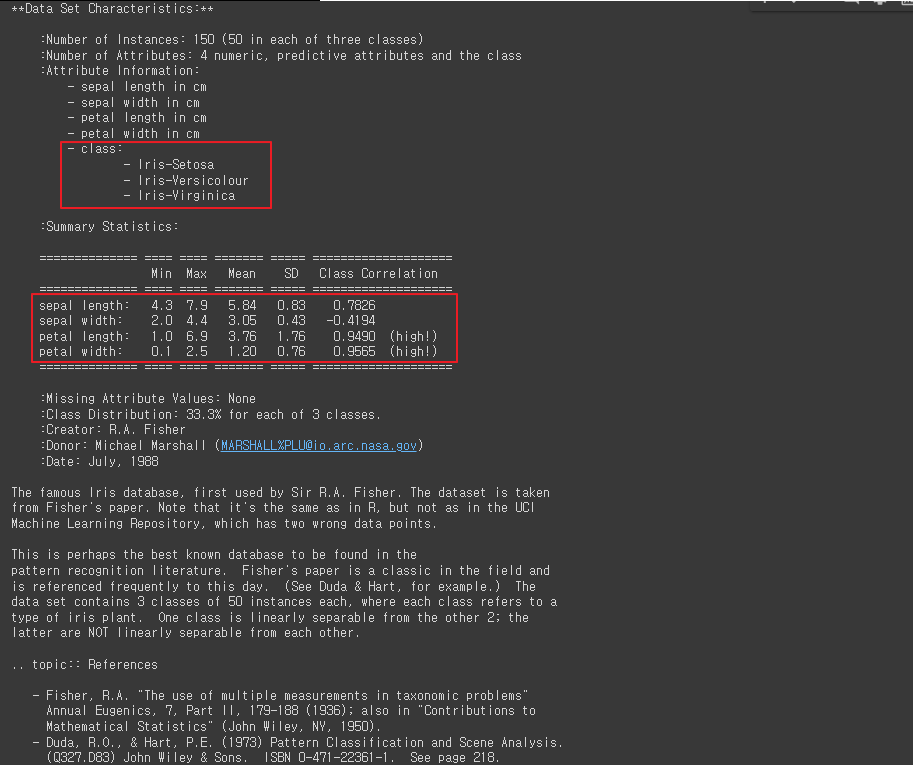
- iris 객체의 'DESCR' 속성을 출력
: 데이터셋에 대한 설명을 담고 있는 문자열
print(iris['DESCR'])
 |
⏺️ 아이리스 종류(타겟이름)
|
⏺️ 분류 속성(입력변수)
|
- 샘플데이터 결과보기
data = iris['data'] # 샘플데이터, Numpy 배열로 이루어져 있음
data # 결과 보기
  |
- 'feature_names' 키를 사용하여 입력 변수(특징)들의 이름을 가져와
feature_names 변수에 저장
feature_names = iris['feature_names'] # Feauture 데이터의 이름
feature_names
 |
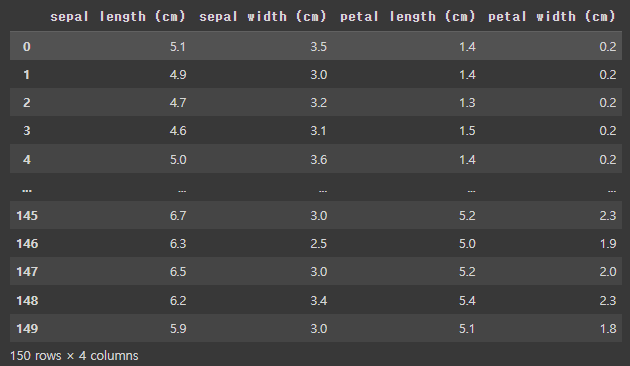
- 판다스로 시각화하기
import pandas as pd
df_iris = pd.DataFrame(data,columns = feature_names)
df_iris
 |
- iris 객체에서 타겟 변수(레이블) 데이터를 추출하여
target 변수에 저장
target = iris['target'] # Label데이터, Numpy 배열로 이루어져 있음
target # 결과보기
target.shape
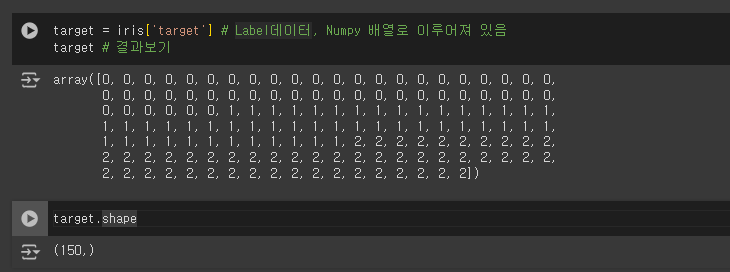 |
| 각 샘플에 대한 클래스 레이블을 나타내는 배열 : 클래스 0 (setosa), : 클래스 1 (versicolor), : 클래스 2 (virginica) target 배열 : 150개의 요소로 구성 (1차원 배열) |
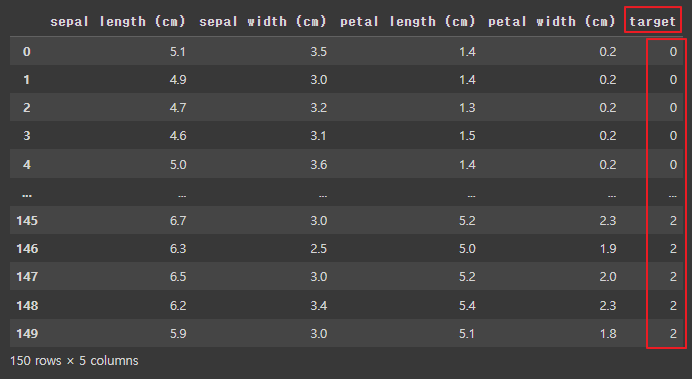
- 파생변수로 만들기
df_iris['target'] = target
df_iris
 |
2. 데이터 나누기
훈련 세트 / 테스트 세트
- train_test_split 함수 가져오기
from sklearn.model_selection import train_test_split
|
- df_iris 데이터프레임 - 입력 변수(X)와 타겟 변수(y)를 나누기
X_train,X_test,y_train,y_test = train_test_split(df_iris.drop('target',1),df_iris['target'],test_size= 0.2, random_state=2024)
| @ train_test_split함수 (독립변수,종속변수,테스트사이즈, 시드값....) 입력 변수(X)와 타겟 변수(y)를훈련 세트와 테스트 세트로 나누는 코드
|
| [결과] <ipython-input-14-983b661006cd>:2: FutureWarning: In a future version of pandas all arguments of DataFrame.drop except for the argument 'labels' will be keyword-only. X_train,X_test,y_train,y_test = train_test_split(df_iris.drop('target',1),df_iris['target'],test_size= 0.2, random_state=2024) |
- 테스트, 정답 데이터 차원보기
X_train.shape, X_test.shape
y_train.shape, y_test.shape
 |
X_train = 훈련세트의 독립변수 행 : 120 / 열 : 4 X_test = 테스트세트의 독립변수 행 : 30 / 열 : 4 y_train = 훈련세트의 종속변수 120 요소(데이터 포인트) y_test = 테스트세트의 종속변수 30 요소(데이터 포인트) |
- 테스트, 정답 데이터 확인
X_train
y_train
 |
| X_train: 훈련 세트의 입력 변수입니다. 이 변수는 모델의 학습에 사용될 데이터를 포함합니다. y_train: 훈련 세트의 타겟 변수입니다. 이 변수는 모델이 예측해야 할 실제 값(레이블)을 포함합니다. |
3. 정확도 계산
SVM은 지도 학습 알고리즘 중 하나로, 주어진 데이터를 분류하거나 회귀하는 데 사용
accuracy_score는 분류 모델의 성능을 측정하는 지표 중 하나로, 예측값과 실제값이 얼마나 일치하는지를 나타냅니다.
- scikit-learn 라이브러리
서포트 벡터 머신(Support Vector Machine, SVM) 모델 가져오기
metrics 모듈에서 정확도를 계산하기 위한 accuracy_score 함수를 가져오기
from sklearn.svm import SVC # 지도학습
from sklearn.metrics import accuracy_score # 정확도 계산
- SVM 모델 생성,
모델을 훈련 세트로 학습
svc=SVC()
svc.fit(X_train, y_train )
 |
- predict 메서드 : 데이터에 대한 예측값을 계산
# svc.predict()메서드는 주어진 데이터에 대한 예측값을 반환함
y_pred = svc.predict(X_test)
y_pred
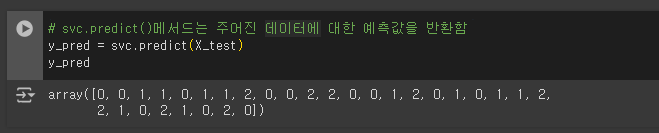 |
| array([0, 0, 1, 1, 0, 1, 1, 2, 0, 0, 2, 2, 0, 0, 1, 2, 0, 1, 0, 1, 1, 2, 2, 1, 0, 2, 1, 0, 2, 0]) 0, 1, 2는 아이리스 데이터셋에서 각각 다음을 의미합니다:
|
|
- 실제값과 예측값을 비교하여 정확도를 계산
print('정답률:',accuracy_score(y_test,y_pred))

| 정답률: 0.8666666666666667 |
|
- 2023으로 바꾼 경우
X_train, X_test, y_train, y_test = train_test_split(df_iris.drop('target', axis=1), df_iris['target'], test_size=0.2, random_state=2023)
y_pred = svc.predict(X_test)
y_pred
print('정답률:',accuracy_score(y_test,y_pred))

| array([2, 1, 1, 2, 1, 2, 1, 1, 0, 1, 0, 1, 0, 2, 0, 2, 0, 1, 0, 0, 1, 0, 2, 1, 0, 0, 0, 2, 1, 0]) 정답률: 1.0 ------------------------------------------------------------------------------------------------------ [ random_state=2023 ] 랜덤 시드를 2023로 변경하니 "정답률이 높아짐!" |
- 꽃씨 예측하기
# 6.2 2.1 4.1 1.5
y_pred = svc.predict([[ 6.2, 2.1, 4.1, 1.5]])
y_pred
 |
|
| /usr/local/lib/python3.10/dist-packages/sklearn/base.py:439: UserWarning: X does not have valid feature names, but SVC was fitted with feature names warnings.warn(array([1]) 1번 꽃씨로 예측함 |
'AI > 머신러닝' 카테고리의 다른 글
| 06. 의사결정 나무(Decision Tree) | 자전거 (0) | 2024.06.11 |
|---|---|
| 05. 선형회귀(Linear Regression) | Rent (0) | 2024.06.11 |
| 04. 데이터 전처리 | 타이타닉 (1) | 2024.06.10 |
| 02. 사이킷런 (Scikit-learn) | LinearSVC (0) | 2024.06.10 |
| 01. 머신러닝 | 데이터 사이트 (0) | 2024.06.10 |



