1. 타이타닉 데이터
- import
import numpy as np
import pandas as pd
- 데이터 불러오기
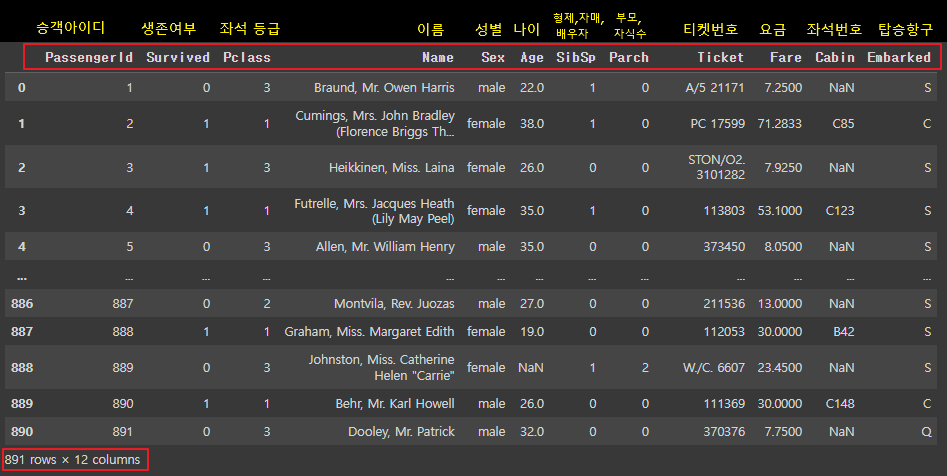 |
데이터 전처리
| - 데이터 정제 작업을 뜻함 - 필요없는 데이터를 삭제하고, null이 있는 행을 처리하고, 정규화/표준화 등의 많은 작업들을 포함 - 머신러닝, 딥러닝 실무에서 전처리가 차지하는 중요도는 50% 이상을 차지한다. |
@. 데이터전처리
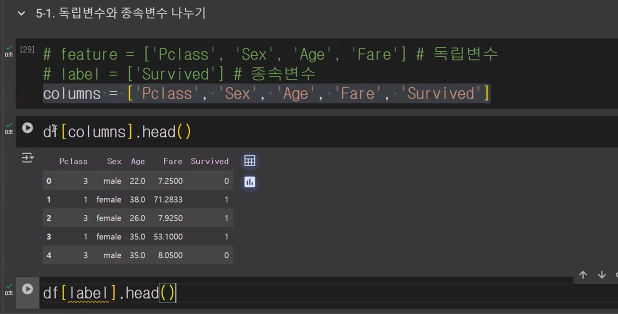
1. 종속변수와 독립변수 나누기
- 종속변수와 독립변수 나누기
feature = ['Sex','Fare','Age','Pclass'] # 독립변수
label = ['Survived'] # 종속 변수
- 표 확인하기
# 독립변수 표로 보기
df[feature].head()
# 종속변수 표로 보기
df[label].head()
 |
- 종속변수 숫자로 보기
# label 숫자 값으로 보기
df[label].value_counts()

| Survived 0 549 1 342 Name: count, dtype: int64 |
@. 데이터전처리
2. 결측치 처리하기
- 결측치 보기
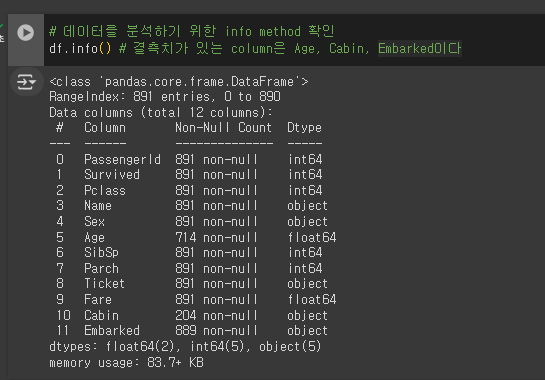
# 데이터를 분석하기 위한 info method 확인
df.info() # 결측치가 있는 column은 Age, Cabin, Embarked이다
# 물론 Cabin, Embarked는 사용하지 않으므로 상관은 없지만 Age의 경우 모델을 만드는데 사용하므로 결측치를 제거한다.
# 누락된 값 즉 결측값의 개수를 계산하는 코드
df.isnull().sum()
  |
- 결측값 비율 계산
df.isnull().mean()
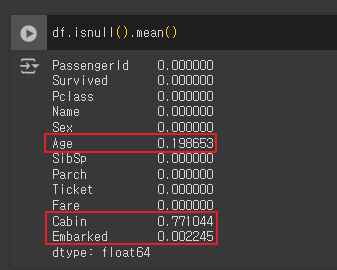 Age, Cabin, Embarked 만 결측값이 존재 Cabin은 큰 비율로 대부분이 결측값 |
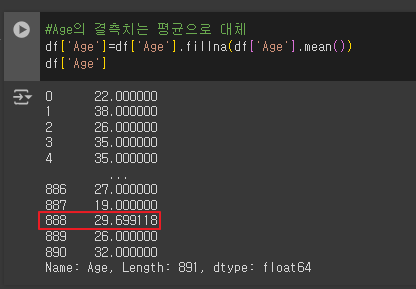
- Age의 결측치를 평균으로 대체
# Age의 결측치는 평균으로 대체
df['Age']=df['Age'].fillna(df['Age'].mean())
df['Age']
 |
@. 데이터전처리
3. 라벨 인코딩 ( Label Encoding)
| - 문자(Categorical)를 수치(Numerical)로 변환 - 성별(Sex) 항목은 object(문자열)인데 수치(Numerical)로 변경해줘야 한다. |
- 정보보기
df.info()
 성별 데이터를 잘 활용하기 위해서 성별이 문자형인데 숫자형으로 바꿔야 할 필요성이 있다. male, female 2가지 경우 밖에 없기 때문에 1, 0으로 처리 탑승항구 데이터를 잘 활용하기 위해서 탑승항구 문자형인데 숫자형으로 바꿔야 할 필요성이 있다. C, Q, S, nul 4가지 경우이기 때문에 라벨인코딩이 필요하다. |
- 성별(Sex)의 수치화
# 성별(Sex)의 값 수치화
df['Sex'].value_counts()
# male, female 2가지 경우 밖에 없기 때문에 1, 0으로 처리를 해야한다.
 성별(Set) 은 male, female 두가지 카테코리만 존재 0,1로 변경 가능하다. |
- 남자는 1, 여자는 0으로 변환하는 함수
# 남자는 1, 여자는 0으로 변환하는 함수
def convert_sex(data):
if data == 'male':
return 1
elif data == 'female':
return 0
df['Sex'] = df['Sex'].apply(convert_sex)
df.head()
 |
- LabelEncoder 사용하기
from sklearn.preprocessing import LabelEncoder
| 범주형 데이터를 숫자로 변환하는 모듈 |
- 'Embarked' 열의 각 값의 빈도수를 계산
# LabelEncoder 객체 생성
la = LabelEncoder()
# 'Embarked' 열의 각 값의 빈도수를 계산
df['Embarked'].value_counts() # null은 제거
 |
- 'Embarked' 열의 각 고유 값을 숫자 레이블로 변환
embarked 변수에 저장
# 해당 항구 이름을 각각 Encoding 하여 숫자로 변경
embarked = la.fit_transform(df['Embarked'])
embarked # C:0 / Q:1 / S :2 / null: 3
 |
- 각 클래스의 원래 값을 확인
la.classes_
# array(['C', 'Q', 'S', nan], dtype=object) => C, Q, S, nan이 각각 0, 1, 2, 3으로 변경되었다.

| array(['C', 'Q', 'S', nan], dtype=object) |
@. 데이터전처리
4. 원 핫 인코딩( One Hot Encoding)
| - 독립적인 데이터는 별도의 column으로 분리하고 각각 column에 해당하는 값에만 1, 나머지는 0값을 가지가 하는 방법이다 예) 머신러닝 알고리즘은 'C:0','Q:1','S:2','nan:3'데이터의 관계성을 찾아 'Q + Q = S'라고 학습할 수 있다. = 관계성을 끊어주기 위해 One Hot Encoding을 사용한다 |
- 'Embarked' 열을 라벨인코딩하여 새로운 열 'Embarked_num'에 저장
df['Embarked_num'] = LabelEncoder().fit_transform(df['Embarked'])
df.head()
 |
- 'Embarked_num' 을 원-핫 인코딩한 데이터프레임을 생성
# Embarked_num의 각 행의 값들이 column에 있는 값과 일치하면 1이 되고 아니면 0이 된다.
pd.get_dummies(df['Embarked_num'])
 |
- 'Embarked' 열을 원-핫 인코딩
: 기존 데이터 프레임에 새로운 열로 추가
: 원래 열 'Embarked'------> 새로운 열 'Embarked_C', 'Embarked_Q', 'Embarked_S'
df = pd.get_dummies(df, columns=['Embarked'])
df.head()
 |
- 데이터 정제 후
사용할 데이터(입력변수)들을 다시 df에 다시 할당
df = df[feature]
df
- 위에 feature 정의한 코드
더보기
feature = ['Sex','Fare','Age','Pclass'] # 독립변수
label = ['Survived'] # 종속 변수
 |
- 'Pclass'와 'Sex' 열 < 원-핫 인코딩(one-hot encoding)>
: 'Pclass' (1, 2, 3) -----> 'Pclass_1', 'Pclass_2', 'Pclass_3' ( 'True'/'False') 세개 열 생성
: 'Sex' ('male' 'female') ------> 'Sex_male', 'Sex_female' ( 'True'/'False') 두개 열 생성
df = pd.get_dummies(df, columns=['Pclass','Sex'])
df.head()
 |
- scikit-learn 라이브러리의 model_selection 모듈
train_test_split 함수 가져오기
from sklearn.model_selection import train_test_split
- 변경
- train_test_split 함수 >> 훈련 세트/테스트 세트로 분할하는 작업
X_train, X_test, y_train, y_test = train_test_split(df.drop('Survived', axis=1), df['Survived'], test_size=0.2, random_state=2024)
| 1. 입력 변수와 타겟 변수 분리 'Survived' 열을 제외한 데이터프레임 --- > 학습할 입력 변수들(X) 'Survived' 열 데이터프레임 --- > 타겟 변수들(y) 2. 데이터 분할
3. 결과 변수
|
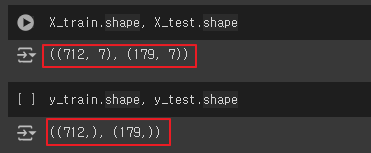
- 결과변수 갯수 출력
X_train.shape, X_test.shape
y_train.shape, y_test.shape
 |
|
|
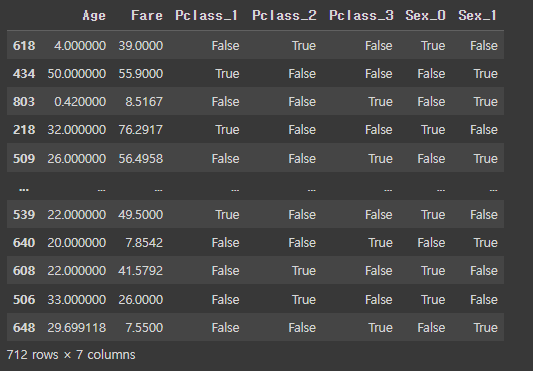
- X_train
: 모델을 학습시키는 데이터
: 훈련 세트의 입력 변수 데이터프레임 출력
X_train
 |
'AI > 머신러닝' 카테고리의 다른 글
| 06. 의사결정 나무(Decision Tree) | 자전거 (0) | 2024.06.11 |
|---|---|
| 05. 선형회귀(Linear Regression) | Rent (0) | 2024.06.11 |
| 03. SVC, accuracy_score | 아이리스 (1) | 2024.06.10 |
| 02. 사이킷런 (Scikit-learn) | LinearSVC (0) | 2024.06.10 |
| 01. 머신러닝 | 데이터 사이트 (0) | 2024.06.10 |



