1. 자연어
(Natural Language Processing, NLP)
- 프로그래밍 언어와 같이 인공적으로 만든 기계언어와 대비되는 단어로, 우리가 일상에서 주로 사용하는 언어
1. 자연어 처리 |
|
2. 자연어처리의 활용 |
|
3. 용어 정리 |
|
2. 토크나이징
- 자연어 처리(NLP)에서 토크나이징(tokenizing)은 텍스트를 더 작은 단위로 분리하는 과정
- 분리된 작은 단위를 토큰(token)이라고 부르며, 일반적으로 단어, 구두점, 숫자, 개별문제일 수 있음
- 토크나이징은 NLP의 초기 단계 중 하나로, 텍스트 데이터가 컴퓨터를 이해하고 처리할 수 있는 형태로 반환
- 토크나이징은 어떻게 하느냐에 따라 성능의 차이가 날 수 있음
1. 영어의 토크나이징 |
|
2. 한국어의 토크나이징 |
|
3. 형태소 분석
- 자연어의 문장은 형태소라는 최소 단위로 분할하고 품사를 판별하는 작업
- 영어 형태소 분석은 형태소마다 띄어쓰기를 해서 문장을 구성하는 것이 기본(분석이 쉬운 편)
- 아시아 계열의 언어분석은 복잡하고 많은 노력이 필요
- 한국이 형태소 분석 라이브러리: KoNLPy
- 명사, 대명사, 수사, 동사, 형용사, 관형사, 부사, 조사, 감탄사 총 9가지를 분석
- Hannanum, KKma, Komoran, Okt 분석기 포함
◼ KoNLPy 라이브러리설치
|
! pip install KoNLPy
|
◼ kolaw 모듈
- konlpy 라이브러리의 kolaw (한국 법률) 모듈 사용하기
|
from konlpy.corpus import kolaw
kolaw.fileids()
|
| ['constitution.txt'] |
◼ 한국 헌법 텍스트 파일의 내용 - law에 저장
|
law = kolaw.open('constitution.txt').read()
law
|
| 대한민국헌법\n\n유구한 역사와 전통에 빛나는 우리 대한국민은 3·1운동으로 건립된 대한민국임시정부의 법통과 불의에 항거한 4·19민주이념을 계승하고, 조국의 민주개혁과 평화적 통일의 사명에 입각하여 정의·인도와 동포애로써 민족의 단결을 공고히 하고, 모든 사회적 폐습과 불의를 타파하며, 자율과 조화를 바탕으로 자유민주적 기본질서를 더욱 확고히 하여 정치·경제·사회·문화의 모든 영역에 있어서 각인의 기회를 균등히 하고, 능력을 최고도로 발휘하게 하며, 자유와 권리에 따르는 책임과 의무를 완수하게 하여, 안으로는 국민생활의 균등한 향상을 기하고 밖으로는 항구적인 세계평화와 인류공영에 이바지함으로써 우리들과 우리들의 자손의 안전과 자유와 행복을 영원히 확보할 것을 다짐하면서 1948년 7월 12일에 제정되고 8차에 걸쳐 개정된 헌법을 이제 국회의 의결을 거쳐 국민투표에 의하여 개정한다.\n\n 제1장 총강\n 제1조 ① 대한민국은 민주공화국이다.\n②대한민국의 주권은 국민에게 있고, 모든 권력은 국민으로부터 나온다.\n 제2조 ① 대한민국의 국민이 되는 요건은 법률로 정한다.\n②국가는 법률이 정하는 바에 의하여 재외국민을 보호할 의무를 진다.\n 제3조 대한민국의 영토는 한반도와 그 부속도서로 한다.\n 제4조 대한민국은 통일을 지향하며, 자유민주적 기본질서에 입각한 평화적 통일 정책을 수립하고 이를 추진한다.\n 제5조 ① 대한민국은 국제평화의 유지에 노력하고 침략적 전쟁을 부인한다.\n②국군은 국가의 안전보장과 국토방위의 신성한 의무를 수행함을 사명으로 하며, 그 정치적 중립성은 준수된다.\n 제6조 ① 헌법에 의하여 체결·공포된 조약과 일반적으로 승인된 국제법규는 국내법과 같은 효력을 가진다.\n②외국인은 국제법과 조약이 정하는 바에 의하여 그 지위가 보장된다.\n 제7조 ① 공무원은 국민전체에 대한 봉사자이며, 국민에 대하여 책임을 진다.\n②공무원의 신분과 정치적 중립성은 법률이 정하는 바에 의하여 보장된다.\n 제8조 ①..... |
◼ kobill
- KoNLPy 라이브러리에 kobill(국회법안 파일)을 모듈 사용
|
from konlpy.corpus import kobill
kobill.fileids()
|
| ['1809895.txt', '1809894.txt', '1809899.txt', '1809893.txt', '1809896.txt', '1809890.txt', '1809897.txt', '1809898.txt', '1809891.txt', '1809892.txt'] |
◼ 특정 법안 텍스트 파일의 내용 - bill에 저장
|
bill = kobill.open('1809895.txt').read()
bill
|
| 하도급거래 공정화에 관한 법률 일부개정법률안\n\n(유선호의원 대표발의 )\n\n 의 안\n 번 호\n\n9895\n\n발의연월일 : 2010. 11. 15.\n\n발 의 자 : 유선호․강기갑․김효석 \n\n조승수ㆍ최문순ㆍ조영택 \n\n문학진ㆍ백재현ㆍ송민순 \n\n박은수ㆍ정동영ㆍ김춘진 \n\n김재윤ㆍ우윤근ㆍ이성남 \n\n이종걸 의원(16인)\n\n제안이유 및 주요내용\n\n 원․수급사업자 사이의 하도급거래는 외형적으로 공정한 계약을 체\n\n결할지라도 교섭력에서 절대 우위에 있는 원사업자에 의한 불공정한 \n\n행위의 가능성은 여전히 상존하고 있음. 또한 수급사업자는 원사업자\n\n의 부당행위에 의하여 손해를 입게 된 경우에도 입증의 부담을 안기 \n\n때문에 민사소송에 의한 피해구제도 쉽지 않은 실정임. \n\n 이에 서면에 의한 계약을 따르지 않을 경우 벌금에 처하도록 하고, \n\n손해배상에 있어서 입증책임을 원사업자에게 전환시키며, 법원이 추정\n\n에 의한 손해액의 인정을 할 수 있게 하여 수급사업자가 소송을 용의\n\n- 1 -\n\n\x0c- 2 -\n\n하게 진행할 수 있도록 함으로써 비대칭적인 교섭력과 정보력의 차이\n\n를 보완하고, 나아가 공정한 하도급거래 질서가 유지․발전 되도록 하\n\n려는 것임(안 제35조 및 제36조 신설). \n\n\x0c법률 제 호\n\n하도급거래 공정화에 관한 법률 일부개정법률안\n\n하도급거래 공정화에 관한 법률 일부를 다음과 같이 개정한다.\n\n제30조제2항제1호 및 제2호를 각각 제2호 및 제3호로 하고, 같은 항에 \n\n제1호를 다음과 같이 신설한다.\n\n 1. 제3조제1항부터 제4항까지 및 제9항을 위반한 자\n\n제35조 및 제36조를 각각 다음과 같이 신설한다.\n\n제35조(손해배상책임) 원사업자가 이 법을 위반함으로써 손해를 입은 \n\n자가 있는 경우에는 그 자의 손해에 대하여 해당 원사업자는 배상\n\n책임을 진다. 다만, 해당 원사업자가 고의 또는.... |
◼ KoNLPy 라이브러리를 사용하여 다양한 형태소 분석기를 초기화
|
from konlpy.tag import *
hannanum = Hannanum()
kkma = Kkma()
komoran = Komoran()
okt = Okt()
|
|
◼ 슬라이싱(slicing) : law 변수에 저장된 문자열의 처음 100자를 추출
- Hannanum
|
law[:100]
|
| 대한민국헌법 유구한 역사와 전통에 빛나는 우리 대한국민은 3·1운동으로 건립된 대한민국임시정부의 법통과 불의에 항거한 4·19민주이념을 계승하고, 조국의 민주개혁과 평화적 통일의 |
◼ 분석기 이용 - 명사 추출
|
# 명사만 추출
okt.nouns(law[:100])
|
| ['대한민국', '헌법', '유구', '역사', '전통', '우리', '국민', '운동', '건립', '대한민국', '임시정부', '법', '통과', '불의', '항거', '민주', '이념', '계승', '조국', '민주', '개혁', '평화', '통일'] |
◼ Okt 형태소 분석기를 사용
- law 변수의 처음 100자에 대해 형태소 분석
- 각 형태소에 대해 품사 태깅을 수행
|
okt.pos(law[:100])
|
| [('대한민국', 'Noun'), ('헌법', 'Noun'), ('\n\n', 'Foreign'), ('유구', 'Noun'), ('한', 'Josa'), ('역사', 'Noun'), ('와', 'Josa'), ('전통', 'Noun'), ('에', 'Josa'), ('빛나는', 'Verb'), ('우리', 'Noun'), ('대', 'Modifier'), ('한', 'Modifier'), ('국민', 'Noun'), ('은', 'Josa'), ('3', 'Number'), ('·', 'Punctuation'), ('1', 'Number'), ('운동', 'Noun'), ('으로', 'Josa'), ('건립', 'Noun'), ('된', 'Verb'), ('대한민국', 'Noun'), ('임시정부', 'Noun'), ('의', 'Josa'), ('법', 'Noun'), ('통과', 'Noun'), ('불의', 'Noun'), ('에', 'Josa'), ('항거', 'Noun'), ('한', 'Josa'), ('4', 'Number'), ('·', 'Punctuation'), ('19', 'Number'), ('민주', 'Noun'), ('이념', 'Noun'), ('을', 'Josa'), ('계승', 'Noun'), ('하고', 'Josa'), (',', 'Punctuation'), ('조국', 'Noun'), ('의', 'Josa'), ('민주', 'Noun'), ('개혁', 'Noun'), ('과', 'Josa'), ('평화', 'Noun'), ('적', 'Suffix'), ('통일', 'Noun'), ('의', 'Josa')] |
◼ Okt 형태소 분석기 : 각 형태소의 품사 태그 세트출력
|
okt.tagset
|
| {'Adjective': '형용사', 'Adverb': '부사', 'Alpha': '알파벳', 'Conjunction': '접속사', 'Determiner': '관형사', 'Eomi': '어미', 'Exclamation': '감탄사', 'Foreign': '외국어, 한자 및 기타기호', 'Hashtag': '트위터 해쉬태그', 'Josa': '조사', 'KoreanParticle': '(ex: ㅋㅋ)', 'Noun': '명사', 'Number': '숫자', 'PreEomi': '선어말어미', 'Punctuation': '구두점', 'ScreenName': '트위터 아이디', 'Suffix': '접미사', 'Unknown': '미등록어', 'Verb': '동사'} |
◼ 띄어쓰기(X) - 형태소 분석, 각 형태소에 대해 품사 태깅
|
text = '아버지가방에들어가신다'
okt.pos(text)
|
| [('아버지', 'Noun'), ('가방', 'Noun'), ('에', 'Josa'), ('들어가신다', 'Verb')] |
◼ 띄어쓰기(O) - 형태소 분석, 각 형태소에 대해 품사 태깅
|
text = '아버지가 방에 들어가신다'
okt.pos(text)
|
| [('아버지', 'Noun'), ('가', 'Josa'), ('방', 'Noun'), ('에', 'Josa'), ('들어가신다', 'Verb')] |
|
◼ Okt 형태소 분석기 : 형태소와 품사 출력
|
okt.pos('오늘 날씨가 참 꾸리꾸리 하네욬ㅋㅋㅋ')
|
| [('오늘', 'Noun'), ('날씨', 'Noun'), ('가', 'Josa'), ('참', 'Verb'), ('꾸리', 'Noun'), ('꾸리', 'Noun'), ('하네욬', 'Noun'), ('ㅋㅋㅋ', 'KoreanParticle')] |
|
◼ 원형 복원(normalization): 각 단어를 그 뿌리 단어 형태로 변환
|
# norm = True : 각 형태소에 대한 원형으로 처리
okt.pos('오늘 날씨가 참 꾸리꾸리 하네욬ㅋㅋㅋ',norm=True)
|
| [('오늘', 'Noun'), ('날씨', 'Noun'), ('가', 'Josa'), ('참', 'Verb'), ('꾸리', 'Noun'), ('꾸리', 'Noun'), ('하네요', 'Verb'), ('ㅋㅋㅋ', 'KoreanParticle')] |
| 원형 복원 (Normalization): norm=True 각 단어를 문맥에 맞추어 원형으로 복원합니다. 예를 들어, "참"은 "참다"의 원형으로 복원됩니다. |
◼ 어간 추출 (Stemming) : 원형 복원 +원형을 기반으로 한 추가적인 어간 추출
|
# stem=True: 원형으로 변경
okt.pos('오늘 날씨가 참 꾸리꾸리 하네욬ㅋㅋㅋ',norm=True,stem=True)
|
| [('오늘', 'Noun'), ('날씨', 'Noun'), ('가', 'Josa'), ('차다', 'Verb'), ('꾸리', 'Noun'), ('꾸리', 'Noun'), ('하다', 'Verb'), ('ㅋㅋㅋ', 'KoreanParticle')] |
| 어간 추출 (Stemming): stem=True 원형 복원 외에도 단어의 기본적인 어간을 추출하여 표준화된 형태로 변환합니다. 예를 들어, "참다"에서는 "참"의 어간을 추출하여 "참"으로 표현합니다. |
4. 워드 클라우드
- 핵심 단어를 시각화하는 기법
- 문서의 키워드. 개념 등을 직관적으로 파악할 수 있게 핵심 단어를 시각적으로 돋보이게 하는 기법
◼ 워드 클라우드 설치
|
! pip install wordcloud
|
◼ 워드 클라우드 사용
|
from wordcloud import WordCloud
|
◼ 파일넣기
|
text = open('/content/drive/MyDrive/1. KDT/7. 자연어처리/데이터/alice.txt').read()
|
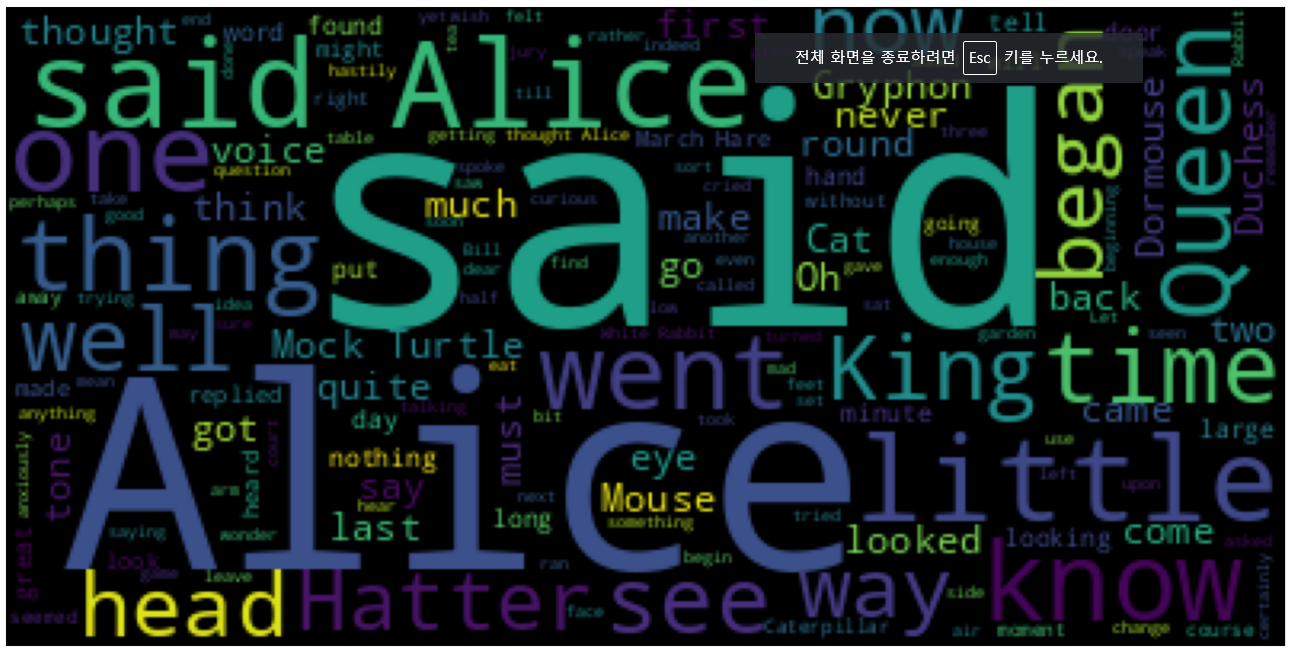
◼ generate() : 단어별 출현 빈도수를 비율로 반환하는 객체를 생성
|
# generate() : 단어별 출현 빈도수를 비율로 반환하는 객체를 생성
wordcloud = WordCloud().generate(text)
wordcloud
|
| <wordcloud.wordcloud.WordCloud at 0x7eed9edd2830> |
◼ 단어들의 상대적인 출현 빈도
|
wordcloud.words_
|
| {'said': 1.0, 'Alice': 0.7225433526011561, 'said Alice': 0.3352601156069364, 'little': 0.31213872832369943, 'one': 0.29190751445086704, 'know': 0.26011560693641617, 'went': 0.2398843930635838, 'thing': 0.23121387283236994, 'time': 0.22254335260115607, 'Queen': 0.21965317919075145, 'see': 0.1936416184971098, 'King': 0.18497109826589594, ..... 'kept': 0.03757225433526012, 'used': 0.03757225433526012, 'lesson': 0.03757225433526012, 'always': 0.03757225433526012, 'Dodo': 0.03757225433526012, 'whole': 0.03757225433526012, 'better': 0.03757225433526012, 'room': 0.03757225433526012, 'gone': 0.03757225433526012, 'remark': 0.03757225433526012, 'cook': 0.03757225433526012, 'Adventures': 0.03468208092485549, 'CHAPTER': 0.03468208092485549, 'many': 0.03468208092485549, 'near': 0.03468208092485549, 'among': 0.03468208092485549, 'name': 0.03468208092485549, 'Dinah': 0.03468208092485549, 'afraid': 0.03468208092485549} |
◼ 시각화로 확인하기
|
import matplotlib.pyplot as plt
plt.figure(figsize = (15, 10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
|
 |
◼ max_words
- 워드 클라우드에 표시되는 단어의 개수를 설정
|
wordcloud = WordCloud(max_words = 100).generate(text)
plt.figure(figsize = (15, 10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
|
 |
◼ 글씨체 설정
|
# 글씨체
!apt-get update -qq
!apt-get install fonts-nanum* -qq
|
◼ 'Nanum' 폰트들을 찾아주기
|
import matplotlib.font_manager as fm
sys_font = fm.findSystemFonts()
[f for f in sys_font if 'Nanum' in f]
|
| ['/usr/share/fonts/truetype/nanum/NanumBarunGothicBold.ttf', '/usr/share/fonts/truetype/nanum/NanumSquare_acR.ttf', '/usr/share/fonts/truetype/nanum/NanumBarunpenR.ttf', '/usr/share/fonts/truetype/nanum/NanumGothicEcoExtraBold.ttf', '/usr/share/fonts/truetype/nanum/NanumGothicCodingBold.ttf', '/usr/share/fonts/truetype/nanum/NanumMyeongjoBold.ttf', '/usr/share/fonts/truetype/nanum/NanumSquare_acL.ttf', '/usr/share/fonts/truetype/nanum/NanumMyeongjoEcoR.ttf', ...... '/usr/share/fonts/truetype/nanum/NanumSquareB.ttf', '/usr/share/fonts/truetype/nanum/NanumSquare_acEB.ttf', '/usr/share/fonts/truetype/nanum/NanumGothicEcoBold.ttf', '/usr/share/fonts/truetype/nanum/NanumGothic.ttf', '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf', '/usr/share/fonts/truetype/nanum/NanumMyeongjo-YetHangul.ttf', '/usr/share/fonts/truetype/nanum/NanumBarunGothic-YetHangul.ttf', '/usr/share/fonts/truetype/nanum/NanumGothicEco.ttf', '/usr/share/fonts/truetype/nanum/NanumMyeongjoEco.ttf'] |
|
◼ font_path = '원하는 글씨체 입력'
|
wordcloud = WordCloud(max_words = 100,
font_path = '/usr/share/fonts/truetype/nanum/NanumPen.ttf').generate(text)
plt.figure(figsize = (15, 10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
|
 |
◼ 이미지 넣기
|
# 이미지
from PIL import Image
import numpy as np
alice_mask = np.array(Image.open('/content/drive/MyDrive/1. KDT/7. 자연어처리/데이터/alice_mask.png'))
alice_mask
|
| ndarray (900, 900) hide data array([[255, 255, 255, ..., 255, 255, 255], [255, 255, 255, ..., 255, 255, 255], [255, 255, 255, ..., 255, 255, 255], ..., [255, 255, 255, ..., 255, 255, 255], [255, 255, 255, ..., 255, 255, 255], [255, 255, 255, ..., 255, 255, 255]], dtype=uint8)  |
◼ 이미지 안에 워드클라우드 넣기
|
wordcloud = WordCloud(max_words = 100,
font_path = '/usr/share/fonts/truetype/nanum/NanumPen.ttf',
mask = alice_mask,
background_color = 'ivory').generate(text)
plt.figure(figsize = (15, 10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
|
 |
◼ 다른 예시
|
### 문제
# konlpy.corpus 말뭉치 중 kolaw의 "constitution.txt"를 읽어서 명사만 추출하고
# 글자수가 한자인 명사는 제거후 빈도수에 따라 워드클라우드를 지도위에 표시하기
from konlpy.corpus import kolaw
from konlpy.tag import Okt
from collections import Counter
# 불러오기
text = kolaw.open('constitution.txt').read()
# 명사 뽑기
okt = Okt()
noun_text = okt.nouns(text)
# 오름차순 정렬
noun_text.sort(key = lambda x: len(x))
# 불용어 제거
stopword = ['얻지','범한','즈음','가지','자주','이제','붙이','도하','일로','거나','로부터','날로','이내','다운','내지','로서','로써']
noun_text = [word for word in noun_text if word not in stopword]
# 단어 길이가 1이상인 단어만 저장
noun_text = [word for word in noun_text if len(word) > 1]
# 빈도수가 많은 단어 TOP 100을 저장 하기
count = Counter(noun_text)
data = count.most_common(100)
data = dict(data)
# 워드 클라우드 생성
mask = np.array(Image.open('mask 경로'))
wordcloud = WordCloud(max_words=100,
font_path='/usr/share/fonts/truetype/nanum/NanumPen.ttf',
mask=mask,
background_color='ivory').generate_from_frequencies(data)
plt.figure(figsize=(15, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
|
 |
'AI > 자연어처리' 카테고리의 다른 글
| 06. 자연어처리 - 워드 임베딩 (6) | 2024.06.25 |
|---|---|
| 05. 자연어처리 - 임베딩 실습 (0) | 2024.06.25 |
| 04. 자연어처리 - 임베딩 (1) | 2024.06.25 |
| 03. 자연어처리 - 전처리 실습 (0) | 2024.06.24 |
| 02. 자연어처리 - 진행순서 (0) | 2024.06.24 |



