1. 그룹으로 묶기
- 그룹으로 묶기
| group by | 데이터를 그룹으로 묶어 분석할 때 사용 |
# DataFrame을 'group' 열로 그룹화
df.groupby('group')
# DataFrame을 'group' 열로 그룹화하고, 각 그룹의 각 열에 대해 NA/결측값이 아닌 항목의 수
df.groupby('group').count()
# DataFrame을 'group' 열로 그룹화하고, 각 그룹의 숫자형 열에 대해 평균을 계산
df.groupby('group').mean(numeric_only=True)
# DataFrame을 'group' 열로 그룹화하고, 각 그룹의 숫자형 열에 대해 합계를 계산
df.groupby('group').sum(numeric_only=True)
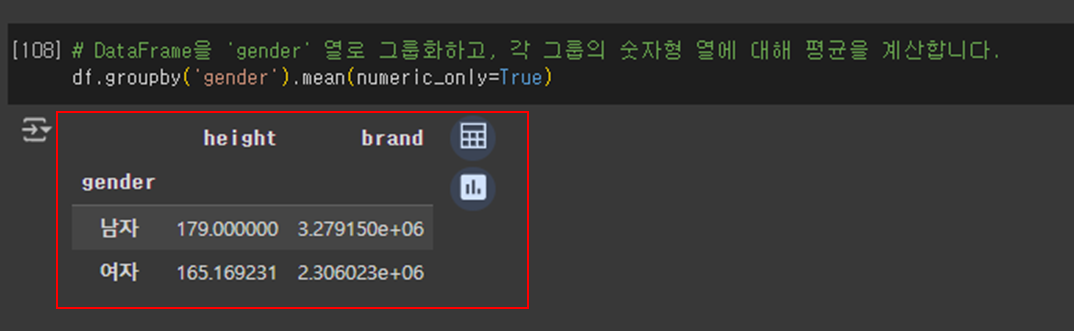
# DataFrame을 'gender' 열로 그룹화하고, 각 그룹의 숫자형 열에 대해 평균을 계산
df.groupby('gender').mean(numeric_only=True)
   |
✅ 문제 풀어보기
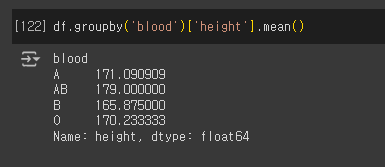
❔ 혈액형별로 그룹을 맺어, 키의 평균값을 확인
df.groupby('blood')['height'].mean()
 |
❔ 혈액형별로 그룹을 맺고, 성별로 또 그룹을 나눈 후 키의 평균값을 확인
df.groupby(['blood', 'gender'])['height'].mean()
 |
2. 중복값 제거
- 중복값 제거
| drop_duplicates() | 분복된 데이터를 제거 |
| value_counts() | - 열의 각 값에 대한 데이터의 개수를 반환. - NaN은 생략 |
| value_counts(dropna=False) | NaN 표기 |
- 중복된 데이터 제거하기
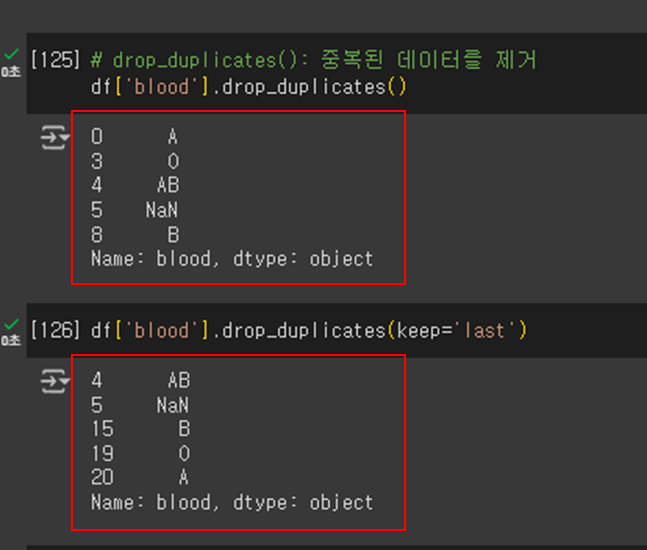
#drop_duplicates() : 중복된 데이터를 제거
df['blood'].drop_duplicates()
# 'blood' 열에서 중복된 값을 제거하고, 마지막 중복 값만 남기기
df['blood'].drop_duplicates(keep='last')
 |
- 데이터 개수 확인
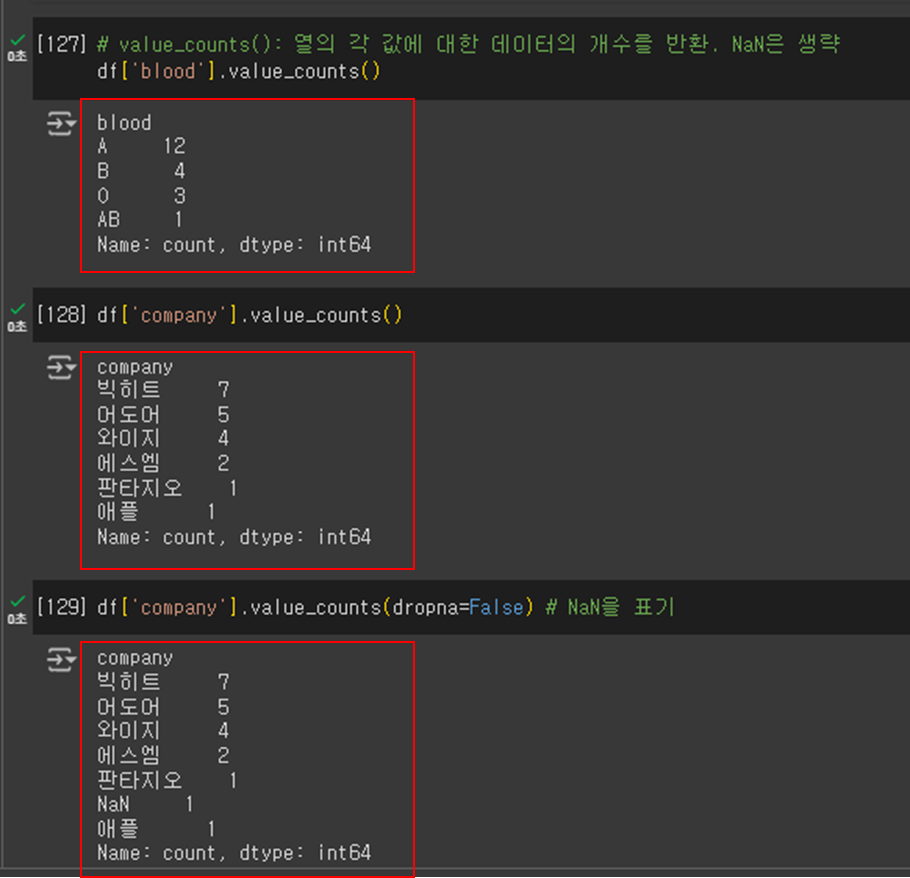
# 'blood' 열의 각 값에 대한 데이터의 개수를 반환 (NaN 값은 생략)
df['blood'].value_counts()
# 'company' 열의 각 값에 대한 데이터의 개수를 반환(NaN 값은 생략)
df['company'].value_counts()
# 'company' 열의 각 값에 대한 데이터의 개수를 반환 (NaN 값도 포함)
df['company'].value_counts(dropna=False)
 |
'데이터분석 > 판다스' 카테고리의 다른 글
| 07. 등수, 날짜타입 (0) | 2024.05.24 |
|---|---|
| 06. 데이터프레임 합치기 (0) | 2024.05.24 |
| 04. 행, 열 추가 삭제, 통계함수 (0) | 2024.05.24 |
| 03. 결측값(NULL, NaN) (0) | 2024.05.24 |
| 02. 데이터 정보, 정렬, 범위, 인덱싱 (0) | 2024.05.24 |



