1. 행, 열 추가 및 삭제하기
- 행을 추가 할떄는 dict 형태를 만들고 append함수를 사용하여 데이터 추가
- ignore_index=True옵션을 추가해야 에러가 발생하지 않음
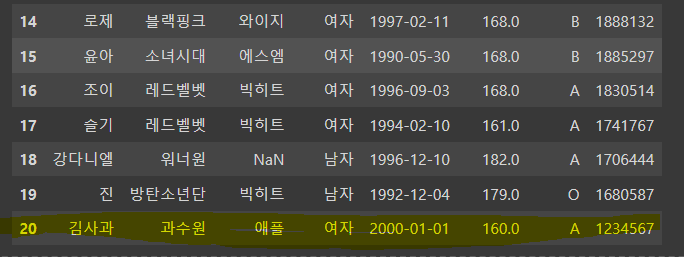
- 행 추가
# 추가할 행 딕셔너리 생성
dic = {
'name' : '김사과',
'group' : '과수원',
'company' : '애플',
'gender' : '여자',
'birthday' : '2000-01-01',
'height' : 160,
'blood' : 'A',
'brand': 1234567
}
# 행추가하기
# (오류) 이번 버전에서 사라짐
# df = df.append(dic, ignore_index=False)
# 행추가하기 concat() : 데이터를 합침, axis = 0 (기본값)
df = pd.concat([df, pd.DataFrame(dic, index=[0])], ignore_index=True)
df
  |
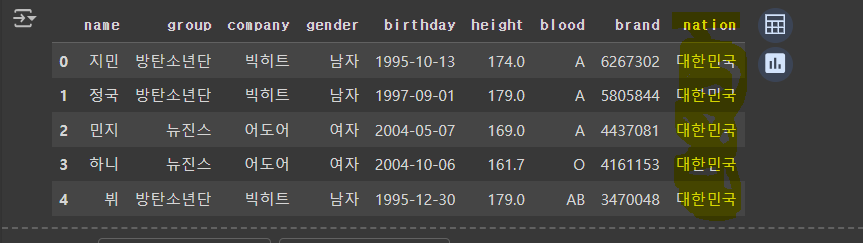
- 열 추가
# 'nation' 열을 생성하고 모든 행에 '대한민국' 값을 할당합니다.
df['nation'] = '대한민국'
df.head()
 |
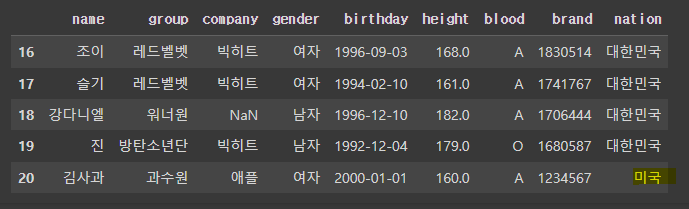
- 값 변경
# 'name' 열의 값이 '김사과'인 행을 찾아 'nation' 값을 '미국'으로 변경합니다.
df.loc[df['name']=='김사과','nation']='미국'
df.tail()
 |
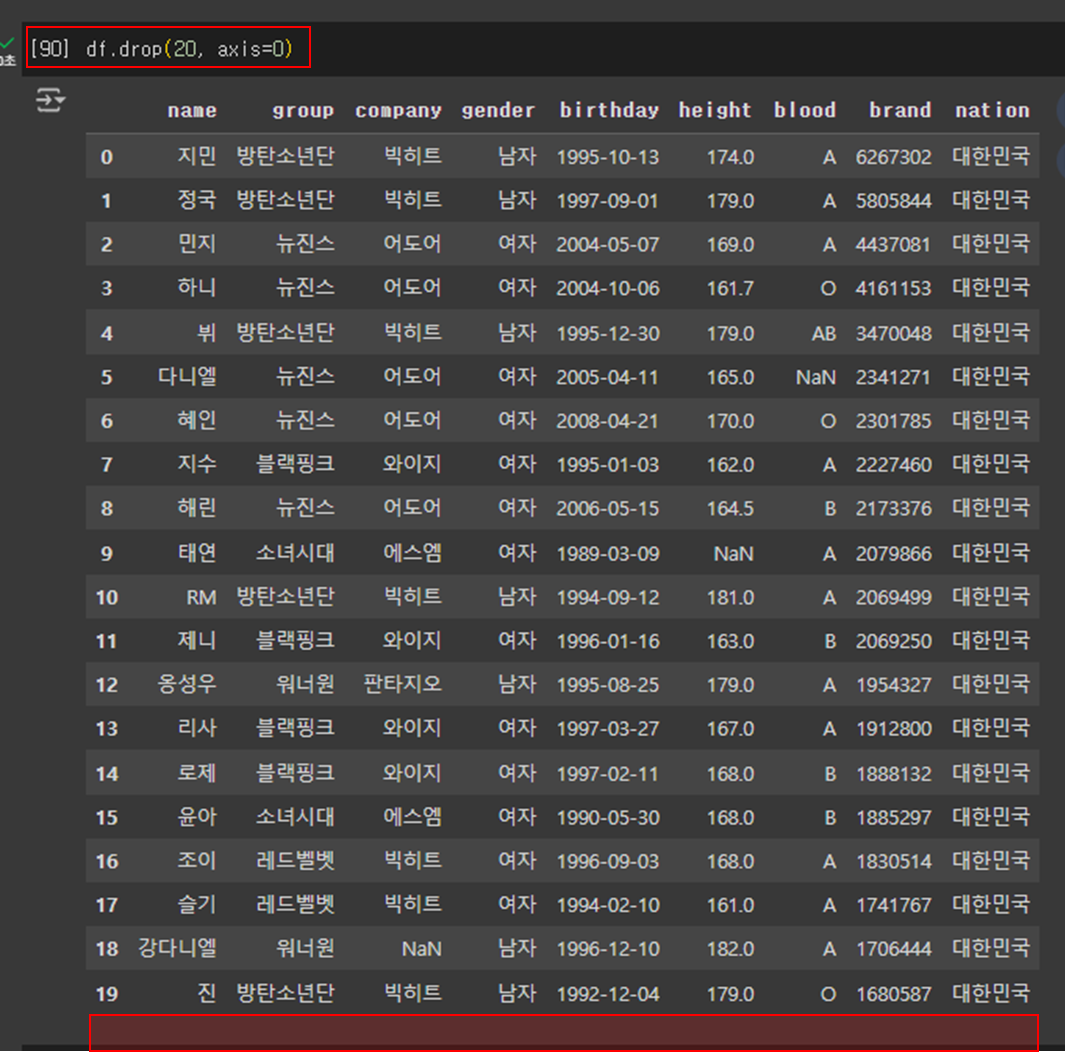
- 행 제거
# 인덱스가 20인 행을 삭제
df.drop(20, axis=0)
# 원본 데이터프레임은 그대로 남아 있음
df.tail()
# 적용방법: 인덱스가 20인 행을 원본 데이터프레임에서 직접 삭제(실행X)
df.drop(20, axis=0, inplace=True)
# 인덱스가 1, 3, 5, 20인 행들을 삭제
df.drop([1,3,5,20],axis=0)
   |
- 열 제거
# 'nation' 열을 삭제합니다.
df.drop(['nation'], axis=1)
# 'group' 및 'nation' 열을 삭제합니다.
df.drop(['group','nation'], axis=1)
  |
2. 통계 함수
- 통계함수
| sum() | 합계 |
| count() | 개수 단, NaN 미 포함 |
| mean() | 평균 값 |
| median() | 중간 값 |
| max() | 최대값 |
| min() | 최소값 |
| var() | - 분산 - 데이터가 평균으로 부터 얼마나 떨어져 있는지 정도 - (데이터 - 평균)**2 |
| std() | - 표준 편차 - 분사에 루트를 씌움 |
- 통계함수
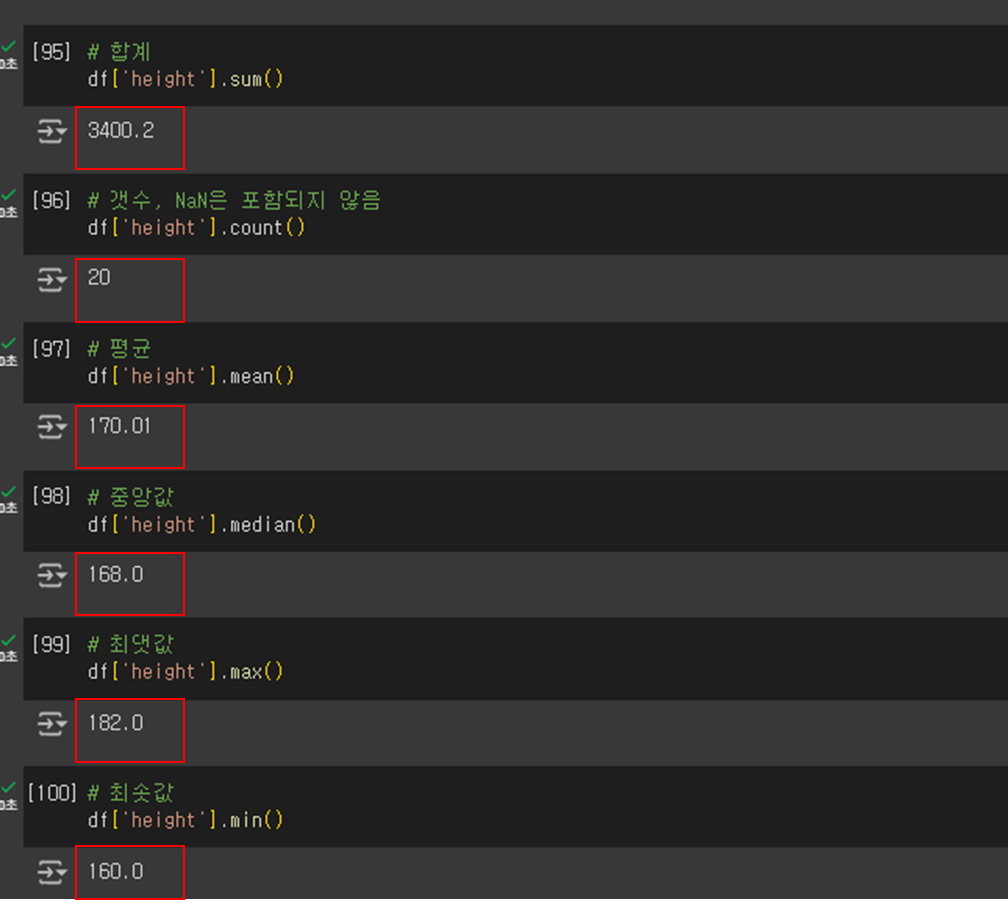
# 합계
df['height'].sum()
# 갯수, NaN은 포함되지 않음
df['height'].count()
# 평균
df['height'].mean()
# 중앙값
df['height'].median()
# 최댓값
df['height'].max()
# 최솟값
df['height'].min()
 |
- 분산, 표준편차
# 분산. 분포에서 테이터가 퍼져있는 정도(데이터가 평균으로 얼마나 퍼져 있는지)
# (데이터-평균)**2을 모두 다 더한 값 / 데이터의 개수
df['height'].var()
# 표준편차 : 분산에 루트를 씌움
df['height'].std()
 |
'데이터분석 > 판다스' 카테고리의 다른 글
| 06. 데이터프레임 합치기 (0) | 2024.05.24 |
|---|---|
| 05. 그룹, 중복값제거 (0) | 2024.05.24 |
| 03. 결측값(NULL, NaN) (0) | 2024.05.24 |
| 02. 데이터 정보, 정렬, 범위, 인덱싱 (0) | 2024.05.24 |
| 01. 판다스(Pandas) (0) | 2024.05.22 |



