1. info( ) : 데이터 정보
- info(): 행(row), 열(column)의 기본적인 정보와 데이터 타입을 반환
df.info()
 * 20개의 데이터 * 열은 8개 * Non-Null Coung: null여부 20 non-null 20개의 데이터가 다 채워져 있다 19 non-null 1개의 데이터가 비워져 있다 object = '엑셀'에서 문자열 float = 실수 int = 정수 |
2. columns : 컬럼명
- columns: 컬럼명 확인 하기
# 컬럼명 확인하기
print(df.columns)
# 컬럼값 변경하기
new_columns = ['name', 'group', 'comapny', 'gender', 'birthday', 'height', 'blood', 'brand']
df.columns = new_columns
# 컬럼명 다시 확인하기
df.columns
# 데이터 프레임 확인하기
df
   |
- shape: 형태
df.shape
 |
3. describe( ) : 데이터 통계
- describe(): 숫자형 데이터 통계 정보를 반환
df.describe()
 * 숫자형 컬럼만 분석 * 객체형(문자열) 데이터 포함하기 describe(include='object') 또는 describe(include='all') |
- describe()
| count() | 개수 단, NaN 미 포함 |
| mean() | 평균 값 |
| std() | - 표준 편차 - 분사에 루트를 씌움 |
| min() | 최솟값 |
| median() | 중간 값 |
| max() | 최대값 |
| sum() | 합계 |
| var() | - 분산 - 데이터가 평균으로 부터 얼마나 떨어져 있는지 정도 - (데이터 - 평균)**2 |
- describe(include = object) : 문자열 타입 데이터 통계보기
# object데이터 통계 보기
df.describe(include = object)
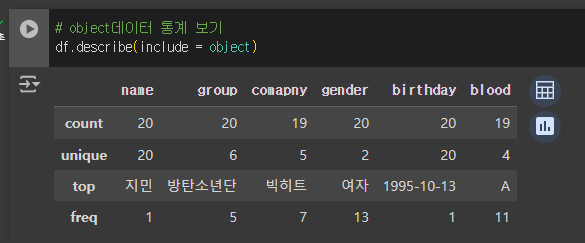 * count: null이 아닌 수 * unique: 중복되지 않은 유니크한 값의 수 이름 20개(다 다름 , unique) 그룹 6개 소속사 5개 성별 2개 생일 20개 * top: 맨위 있는 사람들 표시, 최빈값 (가장 많은 종류) * freq: 최빈값에 있는 갯수 |
| count() | null이 아닌 수 |
| unique() | 중복되지 않은 유니크한 값의 수 |
| top () | 맨위 있는 사람들 표시, 최빈값 (가장 많은 종류) |
| freq() | 최빈값에 있는 갯수 |
4. head( ), tail( ) : 상위/하위 행 출력
- 원하는 개수의 데이터 보기
| head() | 상위 5개의 row를 출력 |
| head(n) | 상위 n개의 row를 출력 |
| tail() | 하위 5개의 row를 출력 |
| tail(n) | 하위 n개의 row를 출력 |
# 원하는 개수의 데이터 보기
df.head() # 상위 5개의 row를 출력
df.tail(2) # 하위 2개의 row를 출력
  |
5. sort_index( ) , sort_valusess : 정렬하기
- 정렬하기
| sort_index() | index로 오른차순 정렬:(기본값) |
| sort_index(ascending=False) | index로 내림차순로 정렬 |
| sort_values(by='컬럼명') | 값에 따른 오름차순 정렬 |
| sort_values(by='컬럼명', ascending=False) | 값에 따른 내림차순 정렬 |
| sort_values(by=['컬럼명1, 컬럼명2']) | 2차 정렬 방식 , list 안에 넣기 |
# 정렬하기
df.sort_index(ascending=True) #index로 오름차순 정렬
df.sort_index(ascending=False) #index로 내림차순 정렬
df.sort_values(by='height') #키로 오름차순 정렬
df.sort_values(by='height', ascending=False) #키로 내림차순 정렬
df.sort_values(by='height', ascending=False, na_position='first') #키로 내림차순 정렬 #null값을 첫번째로
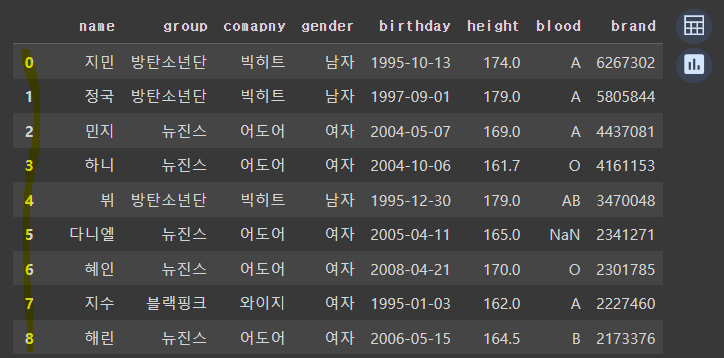
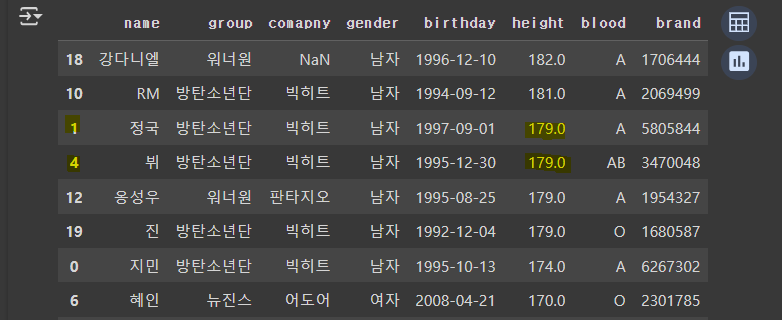
# 1차 정렬 : 키(내림차순), 2차 정렬: 브랜드(내림차순)
df.sort_values(by=['height', 'brand'] , ascending=[False, False])
      |
6. 열선택, 범위선택
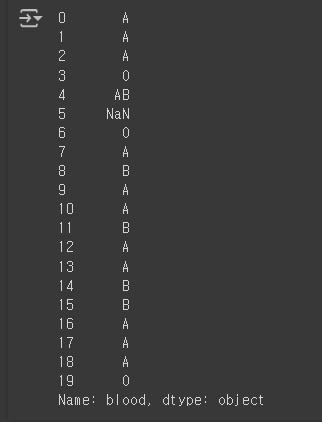
# 데이터프레임의 'blood' 열 선택
df['blood']
# 'blood' 열의 타입 출력
print(type(df['blood']))
# 점 표기법을 사용하여 'blood' 열에 접근
df.blood
   |
- 범위 선택
df[:3]
# 인덱스 0~2
 |
7. 인덱싱
loc, iloc, boolean, isin
- loc인덱싱: 이름 인덱싱, 행과 열 모두 인덱싱과 슬라이싱이 가능
df.loc[행범위, 열지정]
- loc 인덱싱 예시1
# 'name' 열의 모든 값을 선택
df.loc[:,'name']
# 'name' 열의 2에서5 까지, 즉, 5포함
df.loc[2:5,'name']
# 여러개 컬럼 지정할꺼면 list에 넣기
# 'name' ,'gender','height'열에서 2에서5 까지
df.loc[2:5,['name', 'gender', 'height']]
# name 부터 gender 까지
df.loc[2:5,'name':'gender']
 |
 |
- iloc인덱싱 예시2
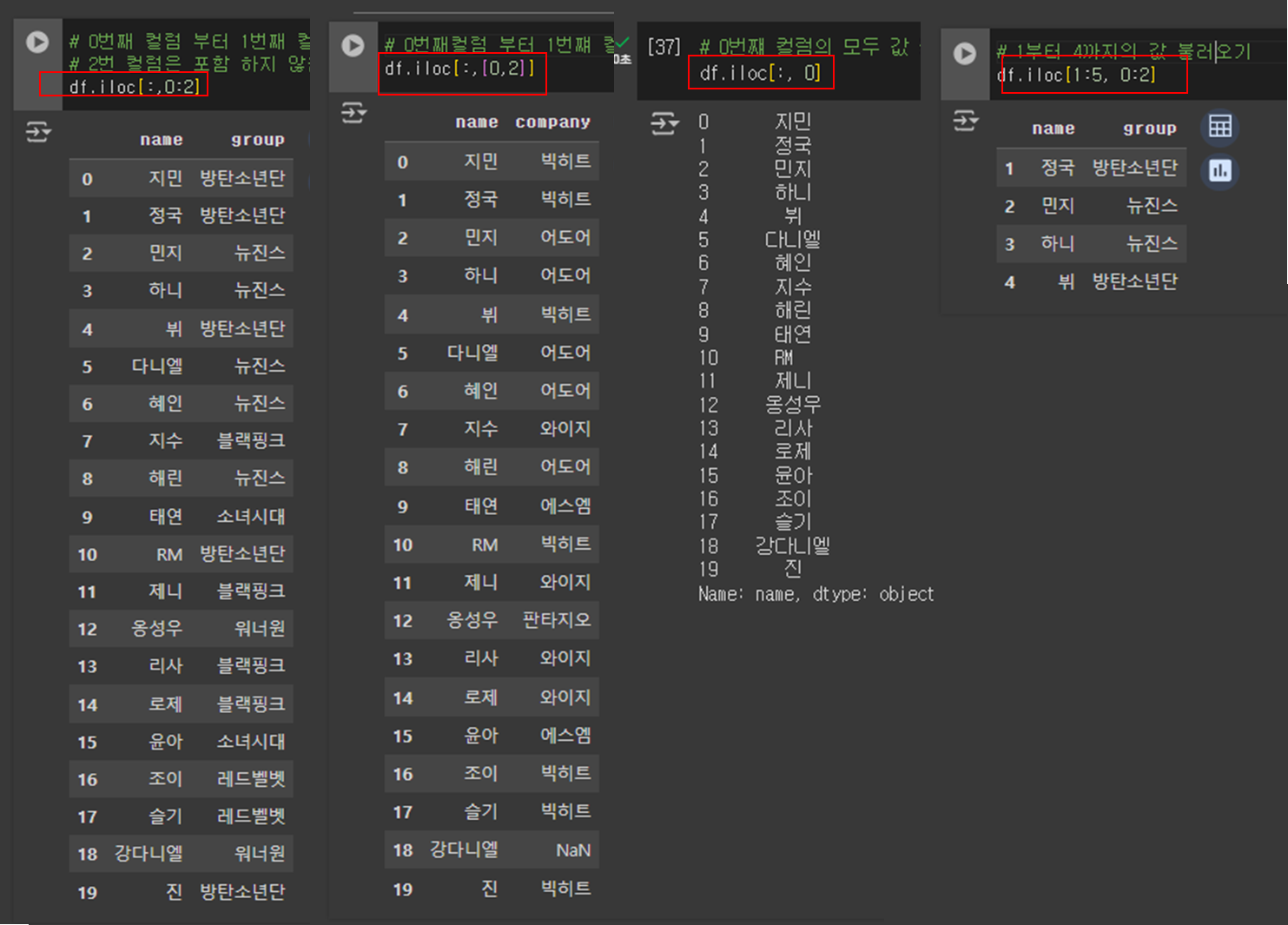
# 0번째 컬럼의 모두 값 불러오기
df.iloc[:, 0]
# 0번째 컬럼 부터 1번째 컬럼 까지의 모든 값 불러오기
# 2번 컬럼은 포함 하지 않음
f.iloc[:,[0,2]]
# 1부터 4까지의 값 불러오기
df.iloc[1:5, 0:2]
# 0번째 컬럼 부터 1번째 컬럼 까지의 모든 값 불러오기
# 2번 컬럼은 포함 하지 않음
df.iloc[:, 0:2]
# 1 부터 4까지의 값 불러오기
df.iloc[1:5, 0:2]
 |
 |
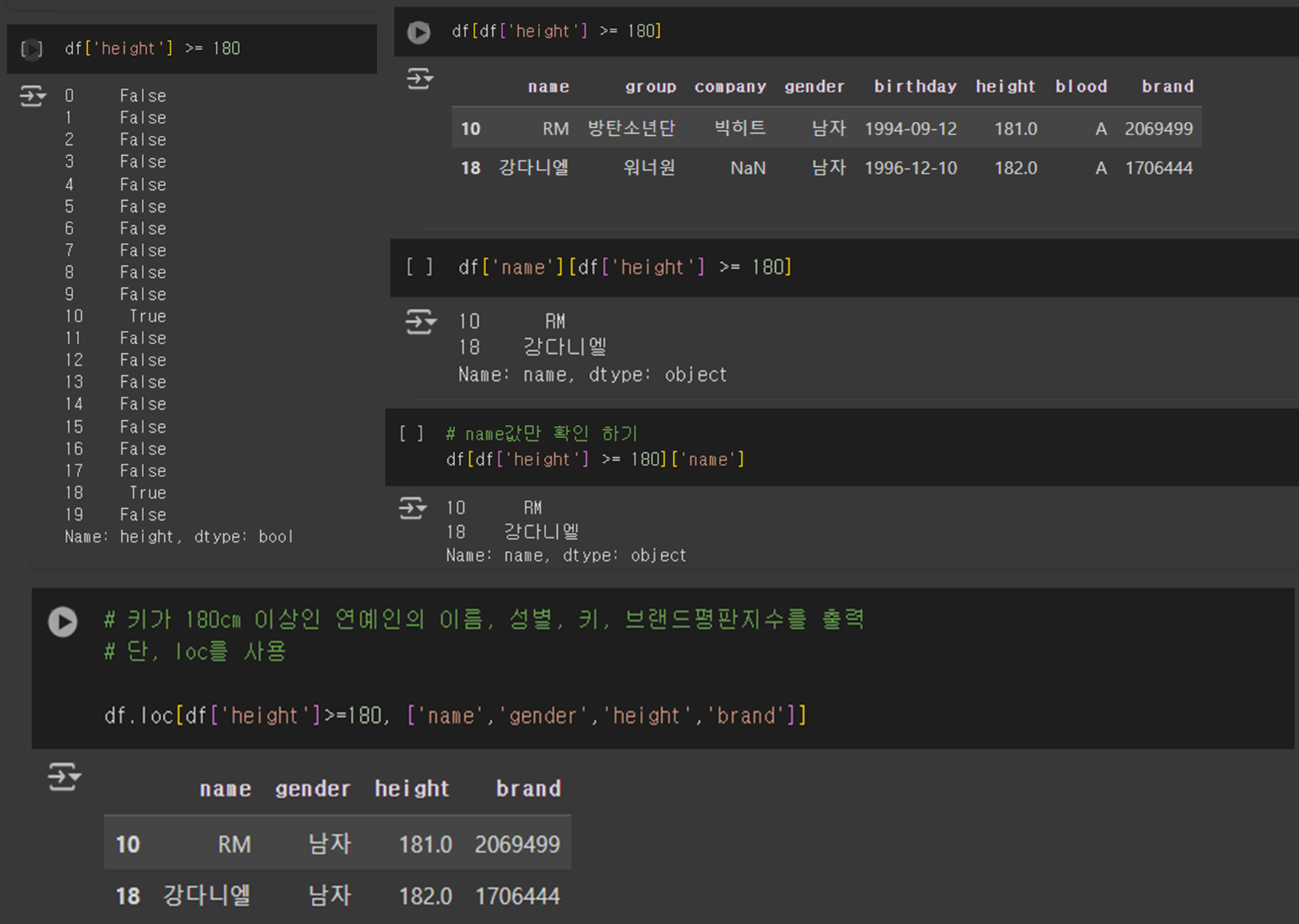
- boolean 인덱싱
df['height'] >= 180
df[df['height'] >= 180]
df['name'][df['height'] >= 180]
# name값만 확인 하기
df[df['height'] >= 180]['name']
# 키가 180cm 이상인 연예인의 이름, 성별, 키, 브랜드평판지수를 출력
# 단, loc를 사용
df.loc[df['height']>=180, ['name','gender','height','brand']]
 |
 |
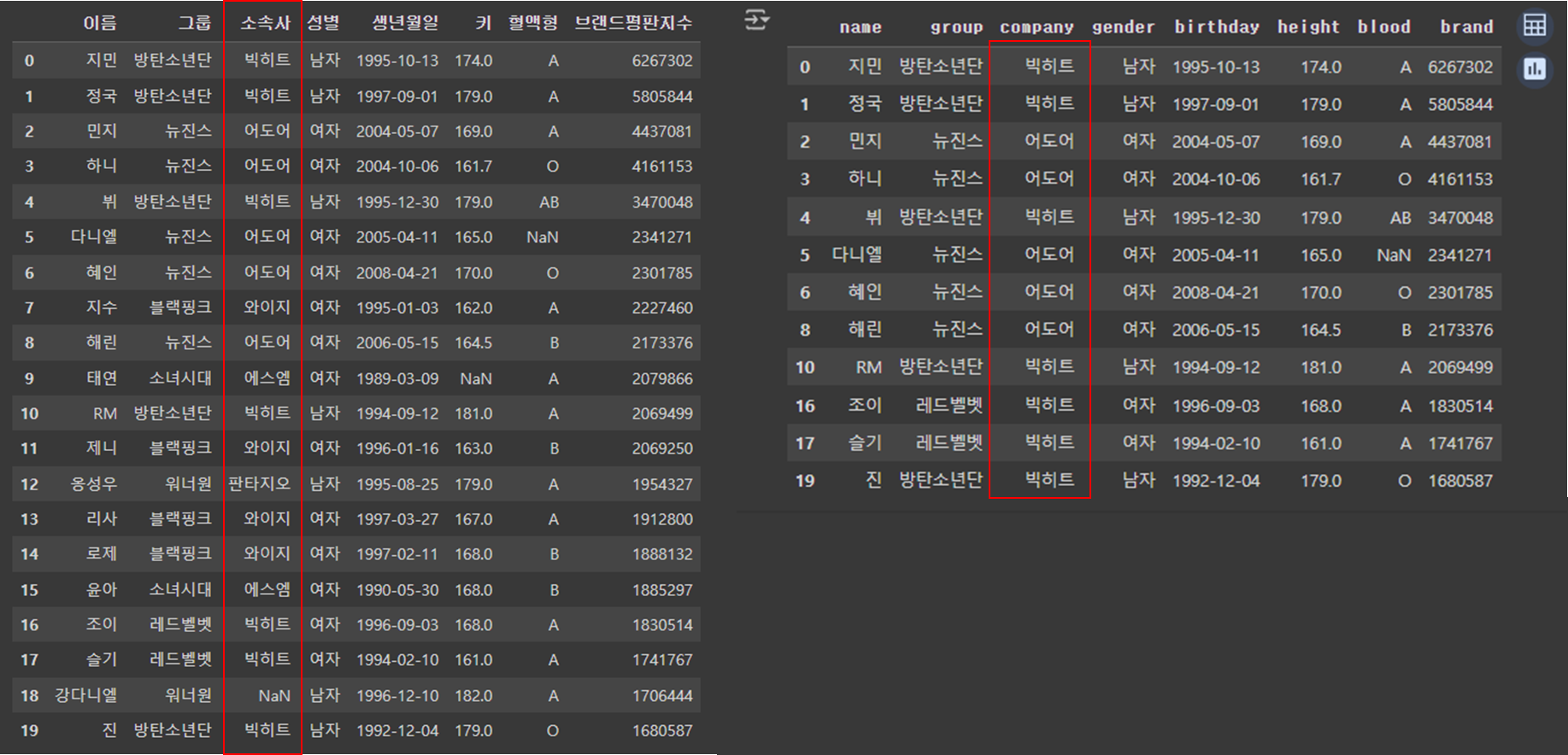
- isin(): 정의한 list에 있는 데이터를 색인
company = ['빅히트', '어도어']
df['comapny'].isin(company)
 |
df[df['company'].isin(company)]
 |
'데이터분석 > 판다스' 카테고리의 다른 글
| 06. 데이터프레임 합치기 (0) | 2024.05.24 |
|---|---|
| 05. 그룹, 중복값제거 (0) | 2024.05.24 |
| 04. 행, 열 추가 삭제, 통계함수 (0) | 2024.05.24 |
| 03. 결측값(NULL, NaN) (0) | 2024.05.24 |
| 01. 판다스(Pandas) (0) | 2024.05.22 |



