1. 계층적 군집화(Hierarchical Clustering)란?
HC는 계층적 군집화(Hierarchical Clustering)를 의미하며,
데이터를 군집화하는 과정과 그 원리를 감각적으로 이해하는 것을 목표로 합니다.
1. 직관적 이해 |
|
2. 특징 |
 |
3. 장단점 |
|
4. HC 적용 전후 |
 |
5. Agglomerative(병합형) vs Divisive(분할형) |
1. Agglomerative (병합형 군집화)병합적 계층적 군집화는 하향식(바텀업, Bottom-up) 접근 방식입니다.즉, 개별 데이터 포인트를 작은 군집에서 시작해 점점 더 큰 군집으로 합쳐 나가는 방식입니다. 과정:
장점:
단점:

분할적 계층적 군집화는 상향식(탑다운, Top-down) 접근 방식입니다. |
6. 덴도그램(Dendrogram) 예시 |
| Bottom-up 방식에서 어떤 순서로 cluster가 묶였는지 보여주는 트리 구조이다. 원하는 level에서 dendrogram을 자름으로써 원하는 기준의 clustering 결과를 얻을 수 있다.  |
2. 적용해보기
고객데이터 | 고객식별번호, 성별, 나이, 연소득, 소비점수
'연소득과 소비점수'를 가지고 병합군집클래스를 이용해서 계층적 군집모델로 학습해 고객층을 나누기
◼ 고객 데이터 | Mall_Customers.csv

◼ import
|
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
|
◼ 데이터 가져오기
|
dataset = pd.read_csv('데이터 위치')
X = dataset.iloc[:, [3, 4]].values
|
◼ 덴드로그램을 사용하여 최적의 군집 수를 찾기ㄱ
|
import scipy.cluster.hierarchy as sch
dendrogram = sch.dendrogram(sch.linkage(X, method = 'ward'))
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Euclidean distances')
plt.show()
|
 |
ㅣ
◼ 계층적 군집화(HC) 모델을 데이터셋에 적용하여 학습
|
from sklearn.cluster import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters = 5, linkage = 'ward')
y_hc = hc.fit_predict(X)
|
| 계층적 군집화는 지도 학습 방식이 아닌 비지도 학습 알고리즘이므로, 여기서의 "학습"은 데이터의 패턴을 찾아 군집을 형성하는 과정을 의미합니다. |
◼ 예측값보기
|
print(y_hc)
|
| [4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 3 4 1 4 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 2 1 2 0 2 0 2 1 2 0 2 0 2 0 2 0 2 1 2 0 2 1 2 0 2 0 2 0 2 0 2 0 2 0 2 1 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2 0 2] |
◼ 고객층 군집을 시각화하기
|
plt.scatter(X[y_hc == 0, 0], X[y_hc == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X[y_hc == 1, 0], X[y_hc == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X[y_hc == 2, 0], X[y_hc == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X[y_hc == 3, 0], X[y_hc == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X[y_hc == 4, 0], X[y_hc == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()
|
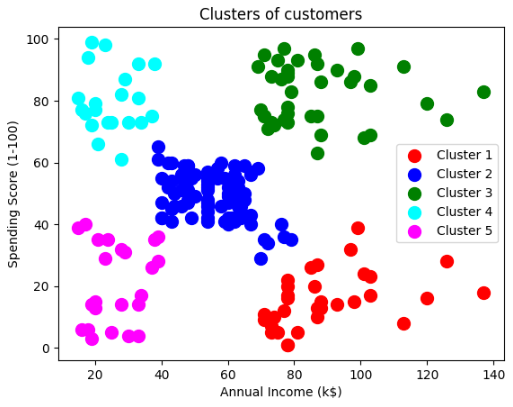 5개의 고객층으로 나눠지는 것을 볼 수 있음 |
'AI > 머신러닝' 카테고리의 다른 글
| 16. 강화학습 | 광고클릭 데이터 (0) | 2024.10.07 |
|---|---|
| 15. 연관 규칙 학습 | Apriori , Eclat (0) | 2024.10.07 |
| 13. 나이브 베이즈 분류기 모델 (0) | 2024.06.18 |
| 12. K-평균 군집화 (KMeans) | Marketing (0) | 2024.06.17 |
| 11. 다양한 모델 성능비교 | Air Quality UCI (0) | 2024.06.17 |



