1. NLI(Natual Language Inference) 실습
- 두개의 문장(전제와 가설) 사이의 논리적 관계를 결정하는 자연어 처리 문제
- 사이트 : https://huggingface.co/Huffon/klue-roberta-base-nli
◼ 설치하기
|
! pip install transformers
|
◼ import
|
from transformers import pipeline, AutoTokenizer
|
|
◼ 객체 만들기
|
classifier = pipeline(
'text-classification',
model = 'Huffon/klue-roberta-base-nli',
return_all_scores = True
)
|
◼ 토크나이저
|
tokenizer = AutoTokenizer.from_pretrained('Huffon/klue-roberta-base-nli')
tokenizer
|
 |
◼ seperate 토큰 확인
|
tokenizer.sep_token
|
| [SEP] |
◼ 모순관계 문장
|
classifier(f'나는 게임을 하는 것을 좋아해 {tokenizer.sep_token}나는 게임을 하는 것이 싫어')
|
 |
◼ 내포하는 문장
|
classifier(f'여러 남성들이 축구를 즐기고 있어요{tokenizer.sep_token} 어떤 남자 들은 스포츠를 하고 있어요')
|
 |
2. 문장요약, 번역, 텍스트 생성 실습
* BART(Sequential Bidirectional AutoRegressive Transformers)
* 허깅페이스에서 개발한 자연어 처리 모델
* 자연어 생성 및 이해 작업을 위해 사전 훈련된 언어모델
* Transformer 아키텍처를 기반으로 양벙향 인코더-디코더 구조를 가지고 있음
* 문장 요약, 번엳 텍스트 생성에 뛰어난 성능을 보여주는 모델
- 사이트: https://huggingface.co/digit82/kobart-summarization
◼ import
|
import torch
from transformers import PreTrainedTokenizerFast
from transformers import BartForConditionalGeneration
|
◼ preTrainedTokenizerFast: 허깅페이스에서 개발한 Rust 기반의 고성능 토크나이저
◼ 객체만들기
|
tokenizer = PreTrainedTokenizerFast.from_pretrained('digit82/kobart-summarization')
model = BartForConditionalGeneration.from_pretrained('digit82/kobart-summarization')
|
◼ text 넣기
|
text = """
중부와 남부지방에 밤사이 폭우가 내린 10일 대전 서구 정뱅이마을에서 주민들이 홍수 피해당한 마을을 살펴보고 있다. 주민들은 새벽 4시쯤 마을 입구에 있는 제방이 무너지고, 강물이 범람해 마을을 덮쳤다고 당시 상황을 설명했다. 주민 박 모씨는 “소를 집에 남겨두고 나와서 죽었다고 생각했는데 잘 버텨줘서 다행이다”라며 “천천히 정리하다 보면 일상으로 돌아갈 수 있을 것”이라고 안도의 한숨을 내쉬었다.
이어 다른 주민 이 모씨는 “과거에도 마을이 잠긴 적 있었지만, 이 정도는 아니었는데 마음이 아프다”라면서도 “그래도 이장이 제방이 무너졌다는 방송을 빨리 해준 덕분에 인명피해가 안 나서 다행이다”라고 말하며 가슴을 쓸어내렸다.새벽에 구조된 주민들은 흑성동 기성종합복지관으로 대피했다. 서구청은 복지관에 대피소를 마련하고 구호물품을 제공할 예정이라고 밝혔다.
"""
|
◼ 줄바꿈 삭제
|
text = text.replace('\n', ' ')
|
◼ text 변수를 토큰화하여 raw_input_ids 리스트를 생성, 출력
|
raw_input_ids = tokenizer.encode(text)
print(raw_input_ids)
|
| [14059, 16660, 20095, 16089, 11786, 15294, 19958, 14556, 19657, 18542, 16458, 16061, 20953, 14045, 10811, 12034, 16503, 14030, 21917, 29878, 14783, 17029, 15901, 12007, 16354, 15326, 15964, 23897, 17412, 21563, 12586, 15901, 14179, 17040, 14082, 14060, 19372, 14113, 15488, 14161, 14119, 15689, 14751, 10223, 13607, 15901, 12007, 18896, 12710, 14117, 14616, 16853, 14490, 15615, 14918, 14169, 14069, 14580, 14128, 15383, 17654, 20296, 15538, 16048, 11264, 14674, 18731, 14246, 17718, 14334, 14536, 13206, 12278, 11264, 14056, 18780, 26187, 14128, 12673, 22378, 17137, 15931, 14972, 14055, 16663, 27286, 14032, 14523, 16047, 14105, 15245, 27919, 14067, 11418, 16367, 14311, 14355, 14918, 14025, 14069, 14580, 14128, 25241, 14279, 15901, 12034, 14693, 9267, 14184, 27735, 14025, 23028, 14202, 19737, 17348, 16873, 14213, 10213, 16944, 18771, 19914, 14025, 14416, 14060, 19372, 18413, 21768, 21801, 17122, 29805, 19785, 25214, 13571, 18518, 14105, 15306, 14056, 18780, 19885, 27479, 24604, 16775, 11763, 9517, 21006, 11229, 10868, 11786, 15181, 9908, 23897, 16816, 11280, 9879, 20382, 16819, 15997, 21403, 25821, 15615, 20953, 16349, 16611, 18565, 25821, 15383, 14712, 14058, 14112, 13699, 10675, 15949, 21131, 27233, 14253, 14130, 1700] |
◼ input_ids 리스트를 만들기
|
input_ids = [tokenizer.bos_token_id] + raw_input_ids + [tokenizer.eos_token_id]
print(input_ids)
|
| [0, 14059, 16660, 20095, 16089, 11786, 15294, 19958, 14556, 19657, 18542, 16458, 16061, 20953, 14045, 10811, 12034, 16503, 14030, 21917, 29878, 14783, 17029, 15901, 12007, 16354, 15326, 15964, 23897, 17412, 21563, 12586, 15901, 14179, 17040, 14082, 14060, 19372, 14113, 15488, 14161, 14119, 15689, 14751, 10223, 13607, 15901, 12007, 18896, 12710, 14117, 14616, 16853, 14490, 15615, 14918, 14169, 14069, 14580, 14128, 15383, 17654, 20296, 15538, 16048, 11264, 14674, 18731, 14246, 17718, 14334, 14536, 13206, 12278, 11264, 14056, 18780, 26187, 14128, 12673, 22378, 17137, 15931, 14972, 14055, 16663, 27286, 14032, 14523, 16047, 14105, 15245, 27919, 14067, 11418, 16367, 14311, 14355, 14918, 14025, 14069, 14580, 14128, 25241, 14279, 15901, 12034, 14693, 9267, 14184, 27735, 14025, 23028, 14202, 19737, 17348, 16873, 14213, 10213, 16944, 18771, 19914, 14025, 14416, 14060, 19372, 18413, 21768, 21801, 17122, 29805, 19785, 25214, 13571, 18518, 14105, 15306, 14056, 18780, 19885, 27479, 24604, 16775, 11763, 9517, 21006, 11229, 10868, 11786, 15181, 9908, 23897, 16816, 11280, 9879, 20382, 16819, 15997, 21403, 25821, 15615, 20953, 16349, 16611, 18565, 25821, 15383, 14712, 14058, 14112, 13699, 10675, 15949, 21131, 27233, 14253, 14130, 1700, 1] |
|
◼ 요약내용 토큰화
|
summary_ids = model.generate(torch.tensor([input_ids]), num_beams=4, max_length=512, eos_token_id=1)
summary_ids
|
| tensor([[ 2, 14059, 16660, 20095, 16089, 11786, 15294, 19958, 14556, 19657, 18542, 16458, 16061, 20953, 14045, 10811, 12034, 16503, 14030, 21917, 14060, 19372, 14113, 15488, 14161, 14119, 15689, 14751, 10223, 13607, 15901, 12007, 18896, 12710, 14117, 14616, 16853, 14490, 17406, 20953, 16349, 16611, 18565, 25821, 15383, 14712, 14058, 14112, 13699, 10675, 15949, 21131, 27233, 14253, 14130, 1]]) |
◼ 요약내용 출력
|
tokenizer.decode(summary_ids.squeeze().tolist(), skip_special_tokens=True)
|
| 중부와 남부지방에 밤사이 폭우가 내린 10일 대전 서구 정뱅이마을에서 주민들이 제방이 무너지고, 강물이 범람해 마을을 덮쳤다고 당시 상황을 설명했으며 서구청은 복지관에 대피소를 마련하고 구호물품을 제공할 예정이라고 밝혔다. |
3. KLUE(Korean Language Understanding Evaludation)
* 한국어 자연어 이해 평가 데이터셋
* 한국어 언어 모델의 동정한 평가를 위한 목적을 8개의 종류가 포함된 공개 데이터셋
* 광범위한 주제와 다양한 스타일을 포괄하기 위해 다양한 출처에서 공개적으로 사용 가능한 한국어 말뭉치를 수집
* 약 62GB 크기의 최종 사전 학습 코퍼스를 구축
◼ 사용목적
* 뉴스 헤드라인 분류
* 문장 유사도 비교
* 자연어 추론
* 개체명 인식
* 관계 추출
* 형태소 및 의존 구문 분석
* 기계 독해 이해
* 대화 상태 추적
◼ 수집
* MODU : 국립국어원에서 배포하는 한국어 말뭉치 모음
* CC-100-Kor : CC-100은 CC-Net을 사용하여 대규모 다국어 웹 크로링 코퍼스를 구축
* 나무위키 : 나무의키는 한국어 웹 기반 백과사전으로 위키백과와 유사하지만 자유로운 형식으로 알려져 있음(2020년3월 2일에 생성된 덤프)
* 뉴스스크롤 : 2011년부터 2020년 까지 발행한 12800000개 뉴스기사로 구성되어 있으며, 뉴스 집계 플랫품애서 수집
* 청원 : 사회적 이슈에 대한 행정 조치를 요청하는 청와대 국민천원 모음, 2017년 8월 부터 2019년 3월 까지 게시된 청와대 국민천원의 기사를 사용
◼ 종류 ['ynat', 'sts', 'nli', 'ner' , 're', 'dp', 'mrc', 'wos']
- ynat: 유투브 비디오 댓글에서 자연스럽게 발생하는 대화
데이터를 이용한 태스크, 주어진 문장에 대해 답변하는 작업 - sts: 두 텍스트의 의미적 유사성을 평가하는 태스크
- nil: 전제와 가설이라는 두 문장 간의 논리적 관계를 판별하는 태스크(참, 거짓, 중립)
- ner: 문장에서 인명, 지명, 기관명 등 특정 개체명을 식별하고 분류하는 태스크
- re: 문장 또는 텍스트에서 개체들 간의 관계를 추출하는 태스크
예) "스티브잡스는 애플의 공동창립자이다" -> 스티브잡스와 애플을 뽑아내고 그 관계를 알려줌 - dp: 문장 내 단어들 간의 문법적 관계를 파악하는 태스크. 각 단어가 어떻게 다른 단어들과 연결되어 있는지(종속성)을 구조적으로 분석
- mrc: 주어진 텍스트와 질문에 대해 답을 추론하거나 생성하는 태스크. 모델이 텍스트를 읽고 이해하여 질문에 답할 수 있도록 함
- wos: Web of Science 데이터베이스에서 추출한 데이터를 활용하는 태스크. 특정 태스크보다느 데이터의 출처를 나타냄
◼ 설치
|
! pip install datasets
! pip install accelerate -U
! pip install transformers[torch]
|
◼ import
|
import datasets
import random
import pandas as pd
import numpy as np
from datasets import load_dataset, ClassLabel, load_metric
from IPython.display import display, HTML
from transformers import AutoTokenizer, pipeline, AutoModelForSequenceClassification, Trainer, TrainingArguments
|
◼ 데이터 불러오기
|
model_checkpoint = 'klue/roberta-base'
batch_size = 64
task = 'ynat'
datasets = load_dataset('klue', task)
|
 |
◼ 데이터셋 확인
|
datasets
|
 |
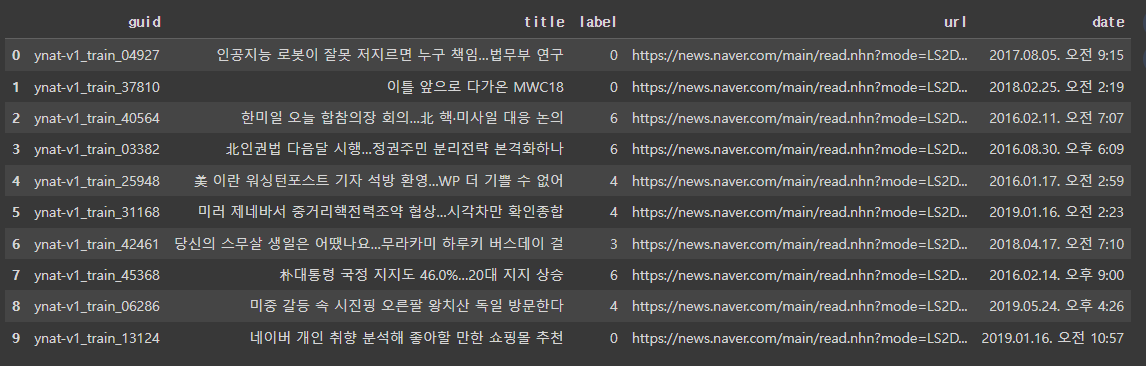
◼ datasets에 train 데이터 인덱스 0~9까지 출력
◼ show_random_elmenets(dataset, num_examples = 10) 함수 만들기
- train데이터에서 랜덤하게 매개 변수에 전달된 갯수 만큼 데이터프레임으로 변환하여 출력
|
def show_random_elmenets(dataset, num_examples=10):
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
return df
show_random_elmenets(datasets['train'])
|
 |
◼ 무작위 예측값 ,실제 레이블 생성
|
fake_preds = np.random.randint(0, 2, size = (64, ))
fake_labels = np.random.randint(0, 2, size = (64, ))
fake_preds, fake_labels
|
| (array([0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0]), array([0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1])) |
◼ f1 측정 지표(metric)를 로드하여 metric 변수에 저장
|
metric = load_metric('f1')
|
 |
◼ metric 객체 생성
|
metric.compute(predictions = fake_preds, references = fake_labels)
|
| {'f1': 0.588235294117647} |
◼ 토크나이저
|
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
|
 |
|
◼ 한국어 텍스트를 토큰화
|
tokenizer('크리스토퍼 놀란, 한국계 셀린 송 감독 ‘패스트 라이브즈’ 극찬 "미묘하게 아름다운 영화"')
print(tokenizer.cls_token_id, tokenizer.eos_token_id)
|
| 0 2 |
◼ tokenizer 객체의 주요 기능과 속성
|
tokenizer
|
  |
◼ 데이터셋의 첫 번째 문장을 확인
|
print(f'문장1: {klue_datasets["train"][0]["title"]}')
|
| 문장1: 유튜브 내달 2일까지 크리에이터 지원 공간 운영 |
◼ 전처리하는 함수
|
def preprocess_function(examples):
return tokenizer(
examples['title'],
truncation=True, # 최대 길이를 초과할 경우 초과된 부분을 잘라냄
return_token_type_ids = False # 토큰 타입 ID를 반환하지 않도록 설정
)
preprocess_function(klue_datasets['train'][:5])
|
| {'input_ids': [[0, 10637, 8474, 22, 2210, 2299, 2118, 28940, 3691, 4101, 3792, 2], [0, 24905, 1042, 4795, 19982, 2129, 121, 6904, 16311, 3, 14392, 2], [0, 4172, 3797, 3728, 2107, 2134, 3777, 904, 6022, 2332, 2113, 2259, 4523, 1380, 2259, 2062, 2], [0, 12417, 2155, 7840, 604, 2859, 3873, 11554, 2522, 1539, 2073, 8446, 6626, 18818, 575, 2], [0, 13203, 2179, 2366, 4197, 7551, 2096, 8542, 2088, 2353, 886, 1244, 4393, 2027, 22, 2207, 8189, 2]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]} |
◼ 전처리 처리하고, 처리된 결과를 encoded_datasets에 저장
|
encoded_datasets = klue_datasets.map(preprocess_function, batched = True)
|
 |
◼ 시퀀스 분류(sequence classification) 작업을 위한 모델을 초기화
|
num_labels = 7 # 분류할 클래스의 개수, 예를 들어 감정분석에서는 긍정, 부정 등의 클래스 수
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels = num_labels)
|
 |
◼ 평가 함수인 compute_metrics를 정의
평가 예측값(eval_pred)을 기반으로 정밀도, 재현율, F1 점수 등 다양한 메트릭을 계산
|
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis = 1)
return metric.compute(predictions = predictions, references = labels, average = 'macro')
|
◼ 모델이 데이터를 어떻게 학습하고 평가할지를 정의
|
metric_name = 'f1'
args = TrainingArguments(
'test-tc',
evaluation_strategy='epoch', # 에폭이 끝날 때마다 평가를 수행하는 평가 전략
save_strategy='epoch', # 모델 체크포인트를 매 에포크마다 저장하는 저장 전략
learning_rate=2e-5, # 학습률 설정
per_device_train_batch_size=batch_size, # 장치 당 학습 배치 크기
per_device_eval_batch_size=batch_size, # 장치 당 평가 배치 크기
num_train_epochs=5, # 학습할 에포크 수
weight_decay=0.01, # 가중치 감소 설정
load_best_model_at_end=True, # 학습이 끝난 후 가장 좋은 성능을 보인 모델을 불러올지 여부
metric_for_best_model=metric_name # 최적의 모델을 결정할 때 사용할 메트릭 지정
)
|
◼ Trainer 객체를 사용하여 모델 학습 과정을 자동화
|
trainer = Trainer(
model,
args,
train_dataset = encoded_datasets['train'],
eval_dataset = encoded_datasets['validation'],
tokenizer = tokenizer,
compute_metrics = compute_metrics
)
trainer.train()
|
 |
◼ 모델을 평가
|
trainer.evaluate()
|
 |
◼ 최적의 성능을 보인 모델 체크포인트 파일의 경로
|
best_model_checkpoint = trainer.state.best_model_checkpoint
best_model_checkpoint
|
  |
◼ 텍스트 분류를 수행하는 파이프라인을 설정
|
classifier = pipeline(
'text-classification',
model = '/content/test-tc/checkpoint-2142',
return_all_scores = True
)
classifier('전주시, 9월까지 가시박 등 생태계 교란 식물 제거')
|
| ''' 0 (IT과학) 1 (경제) 2 (사회) 3 (생활문화) 4 (세계) 5 (스포츠) 6 (정치) ''' 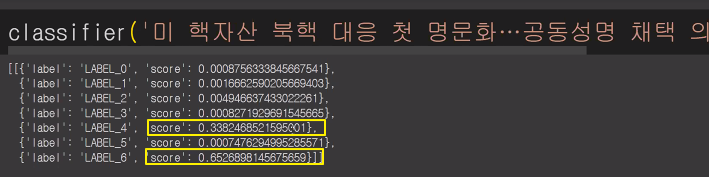  |
@. 팀과제
1. 한국어 금융 뉴스, 긍정, 부정 분류
* https://github.com/ukairia777/finance_sentiment_corpus
2. 다중 클래스 분류 : 두 문장을 입력받아 두 문장의 '얽힘','중립','모순'을 분류해주는 문제
* https://github.com/kakaobrain/kor-nlu-datasets
3. 한국어 혐오 발언 다중 레이블 분류
* https://github.com/adlnlp/K-MHaS
1. 예시) prediction ("ChatGPT의 등장으로 인공지능 스타트업들이 비상이 걸렸다.") [ 부정 ]
2. 예시) prediction ("sent1, sent2") [ 모순 ]
sent1 = '흡연자분들은 발코니가 있는 방이면 발코니에서 흡연하세요."
sent2 = '이 건물은 흡연이 금지됩니다."
3. 예시) prediction("XX들은 왜 그렇게 민폐를 끼치냐?") ['연령차별']
'AI > 자연어처리' 카테고리의 다른 글
| 19. sentence-transformer 활용 (2) | 2025.01.03 |
|---|---|
| 17. 자연어처리를 위한 모델 학습 (0) | 2024.07.11 |
| 16. 문장 임베딩 | GPT (0) | 2024.07.05 |
| 15. 문장임베딩 | BERT (1) | 2024.07.05 |
| 14. 문장 임베딩 | ELmo / Transformer (1) | 2024.07.04 |



