1. 데이터로더(Data Loader)
데이터양이 많을 때 배치 단위로 학습하는 방법을 제공

데이터로더(DataLoader)의 역할
- 배치 처리: 데이터를 지정된 배치 크기로 나누어 모델에 입력으로 제공합니다.
- 셔플(shuffle): 데이터를 섞어서 모델이 데이터의 순서에 의존하지 않도록 합니다. 특히 훈련 데이터에서 사용됩니다.
- 병렬 처리: num_workers 매개변수를 설정하여 데이터를 병렬로 로드하여 속도를 높일 수 있습니다.
- import
|
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as tranforms
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
|
- GPU를 활용할 수 있는지 확인 (런타임 유형 변경 후 런타임 다시 실행)
|
device = 'cuda' if torch.cuda.is_available() else 'cpu' print(device)
|
  GPU가 없는 경우에는 출력은 'cpu' CUDA를 사용할 수 있다면, 출력은 'cuda' |
- scikit-learn에서 제공하는 숫자 이미지 데이터셋인 digits를 로드
: 데이터와 타겟을 출력
|
digits = load_digits()
x_data = digits['data']
y_data = digits['target']
print(x_data.shape)
print(y_data.shape)
|
| (1797, 64) (1797,) |
- 숫자 이미지 데이터셋을 시각화
( 이미지를 2x5 형태로 출력 )
|
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(14, 8))
for i, ax in enumerate(axes.flatten()):
ax.imshow(x_data[i].reshape((8, 8)), cmap='gray')
ax.set_title(y_data[i])
ax.axis('off')
|
 |
- PyTorch를 사용하여 데이터를 텐서 형태로 변환
|
x_data = torch.FloatTensor(x_data)
y_data = torch.LongTensor(y_data)
print(x_data.shape)
print(y_data.shape)
|
x_data = torch.FloatTensor(x_data)
y_data = torch.LongTensor(y_data)
|
| torch.Size([1797, 64]) torch.Size([1797]) 텐서의 형태(모양) 출력 데이터셋에는 1797개의 이미지 데이터가 있고, 각 이미지는 64개의 특성을 가진다 데이터셋에는 1797개의 타겟 값이 있음을 나타냅니다. 각 값은 해당 숫자 이미지의 실제 숫자 |
- 데이터를 훈련 세트와 테스트 세트로 나누기
|
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2, random_state=2024)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
|
| torch.Size([1437, 64]) torch.Size([1437]) torch.Size([360, 64]) torch.Size([360]) |
- DataLoader를 사용하여 데이터셋을 불러오는 과정
|
loader = torch.utils.data.DataLoader(
dataset=list(zip(x_train, y_train))
)
dataset=list(zip(x_train, y_train))
dataset
|
loader = torch.utils.data.DataLoader(dataset=dataset)
dataset=list(zip(x_train, y_train))
dataset
|
[(tensor([ 0., 0., 0., 0., 9., 15., 0., 0., 0., 0., 1., 10., 16., 16., 1., 0., 0., 5., 16., 15., 14., 16., 0., 0., 0., 1., 8., 0., 10., 16., 0., 0., 0., 0., 0., 0., 11., 16., 0., 0., 0., 0., 0., 0., 10., 15., 0., 0., 0., 0., 0., 0., 12., 16., 3., 0., 0., 0., 0., 0., 8., 16., 3., 0.]), tensor(1)), (tensor([ 0., 0., 0., 15., 16., 16., 12., 4., 0., 0., 4., 14., 0., 10., 12., 0., 0., 0., 8., 7., 1., 15., 4., 0., 0., 0., 0., 0., 8., 12., 0., 0., 0., 0., 1., 8., 14., 12., 3., 0., 0., 0., 6., 13., 16., 13., 2., 0., 0., 0., 0., 10., 10., 0., 0., 0., 0., 0., 2., 16., 2., 0., 0., 0.]), ...... (tensor([ 0., 0., 3., 12., 16., 13., 0., 0., 0., 1., 14., 9., 10., 13., 0., 0., 0., 0., 2., 0., 10., 10., 0., 0., 0., 0., 3., 7., 15., 16., 10., 0., 0., 0., 16., 16., 15., 3., 0., 0., 0., 0., 3., 13., 7., 0., 0., 0., 0., 0., 0., 16., 2., 0., 0., 0., 0., 0., 4., 15., 0., 0., 0., 0.]), tensor(7)), (tensor([ 0., 0., 9., 7., 0., 0., 0., 0., 0., 0., 9., 11., 0., 0., 0., 0., 0., 0., 15., 4., 0., 0., 0., 0., 0., 2., 16., 1., 0., 0., 0., 0., 0., 5., 16., 8., 14., 9., 0., 0., 0., 5., 16., 15., 8., 9., 10., 0., 0., 3., 16., 2., 0., 7., 11., 0., 0., 0., 7., 14., 16., 12., 1., 0.]), tensor(6)), ...] |
- 데이터셋을 배치(batch) 단위로 로드,
첫 번째 배치의 이미지를 시각화
|
loader = torch.utils.data.DataLoader(
dataset=list(zip(x_train, y_train)),
batch_size=64,
shuffle=True
)
imgs, labels = next(iter(loader))
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14, 14))
for ax, img, label in zip(axes.flatten(), imgs, labels):
ax.imshow(img.reshape((8, 8)), cmap='gray')
ax.set_title(str(label))
ax.axis('off')
|
 |
DataLoader 설정
시각화
|
- 간단한 신경망 모델을 정의하고, 이를 훈련하는 과정
|
model = nn.Sequential(
nn.Linear(64, 10)
)
optimizer = optim.Adam(model.parameters(), lr=0.01)
epochs = 50
for epoch in range(epochs + 1):
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in loader:
y_pred = model(x_batch)
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_losses = sum_losses + loss
y_prob = nn.Softmax(1)(y_pred)
y_pred_index = torch.argmax(y_prob, axis=1)
acc = (y_batch == y_pred_index).float().sum() / len(y_batch) * 100
sum_accs = sum_accs + acc
avg_loss = sum_losses / len(loader)
avg_acc = sum_accs / len(loader)
print(f'Epoch {epoch:4d}/{epochs} Loss: {avg_loss:.6f} Accuracy: {avg_acc:.2f}%')
|
| Epoch 0/50 Loss: 1.522297 Accuracy: 61.89% Epoch 1/50 Loss: 0.299263 Accuracy: 90.92% Epoch 2/50 Loss: 0.186552 Accuracy: 94.28% Epoch 3/50 Loss: 0.155529 Accuracy: 95.27% Epoch 4/50 Loss: 0.116850 Accuracy: 96.54% Epoch 5/50 Loss: 0.101433 Accuracy: 97.46% Epoch 6/50 Loss: 0.105107 Accuracy: 96.54% ....... Epoch 42/50 Loss: 0.007945 Accuracy: 100.00% Epoch 43/50 Loss: 0.010049 Accuracy: 99.86% Epoch 44/50 Loss: 0.009674 Accuracy: 100.00% Epoch 45/50 Loss: 0.011133 Accuracy: 99.80% Epoch 46/50 Loss: 0.007075 Accuracy: 100.00% Epoch 47/50 Loss: 0.006850 Accuracy: 100.00% Epoch 48/50 Loss: 0.007192 Accuracy: 100.00% Epoch 49/50 Loss: 0.006950 Accuracy: 100.00% Epoch 50/50 Loss: 0.006263 Accuracy: 100.00% |
모델 정의
옵티마이저 설정
학습 루프
주의사항
|
- 주석
더보기
|
model = nn.Sequential(
nn.Linear(64, 10) # 입력 차원 64, 출력 차원 10인 선형 레이어를 정의합니다.
)
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 옵티마이저를 사용하고 학습률은 0.01로 설정합니다.
epochs = 50 # 전체 데이터셋을 50번 반복하여 학습합니다.
for epoch in range(epochs + 1): # 주어진 epoch 수만큼 반복합니다.
sum_losses = 0 # 현재 epoch의 총 손실을 저장할 변수를 초기화합니다.
sum_accs = 0 # 현재 epoch의 총 정확도를 저장할 변수를 초기화합니다.
for x_batch, y_batch in loader: # 데이터 로더에서 배치 단위로 데이터를 가져옵니다.
y_pred = model(x_batch) # 모델에 입력 데이터를 전달하여 예측값을 계산합니다.
loss = nn.CrossEntropyLoss()(y_pred, y_batch) # Cross Entropy 손실 함수를 사용하여 손실을 계산합니다.
optimizer.zero_grad() # 옵티마이저의 gradient를 초기화합니다.
loss.backward() # 손실을 역전파하여 각 파라미터의 gradient를 계산합니다.
optimizer.step() # 옵티마이저를 사용하여 파라미터를 업데이트합니다.
sum_losses = sum_losses + loss # 배치 손실을 현재 epoch의 총 손실에 더합니다.
y_prob = nn.Softmax(dim=1)(y_pred) # 모델의 출력을 소프트맥스 함수를 통해 확률로 변환합니다.
y_pred_index = torch.argmax(y_prob, axis=1) # 예측된 클래스의 인덱스를 가져옵니다.
acc = (y_batch == y_pred_index).float().sum() / len(y_batch) * 100 # 배치의 정확도를 계산합니다.
sum_accs = sum_accs + acc # 배치 정확도를 현재 epoch의 총 정확도에 더합니다.
avg_loss = sum_losses / len(loader) # 전체 데이터셋에 대한 평균 손실을 계산합니다.
avg_acc = sum_accs / len(loader) # 전체 데이터셋에 대한 평균 정확도를 계산합니다.
print(f'Epoch {epoch:4d}/{epochs} Loss: {avg_loss:.6f} Accuracy: {avg_acc:.2f}%') # 현재 epoch의 평균 손실과 정확도를 출력합니다.
|
- 손글씨 숫자 데이터셋에서 테스트 세트의 10번째 데이터를 시각화, 해당 데이터의 레이블을 출력
|
plt.imshow(x_test[10].reshape((8,8)),cmap='gray')
print(y_test[10])
|
| tensor(7) 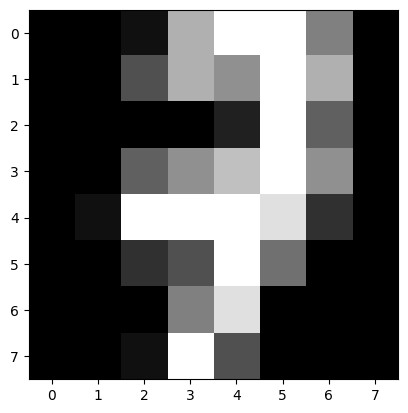 |
- 10번째 데이터에 해당하는 예측값을 출력
|
y_pred=model(x_test)
y_pred[10]
|
| tensor([ -6.4605, -3.0447, -12.9360, -4.3177, -3.6224, -9.9192, -10.9246, 10.5876, -2.3388, 1.4592], grad_fn=<SelectBackward0>) |
- Softmax 함수로 예측된 결과(y_pred)에 대해 확률을 계산
|
y_prob = nn.Softmax(1)(y_pred)
y_prob[10]
|
| tensor([3.9450e-08, 1.2009e-06, 6.0780e-11, 3.3624e-07, 6.7395e-07, 1.2415e-09, 4.5428e-10, 9.9989e-01, 2.4327e-06, 1.0853e-04], grad_fn=<SelectBackward0>) |
- 각 클래스에 해당하는 확률을 순서대로 출력
|
for i in range(10):
print(f'숫자 {i}일 확률:{y_prob[10][i]:.2f}')
|
| 숫자 0일 확률:0.00 숫자 1일 확률:0.00 숫자 2일 확률:0.00 숫자 3일 확률:0.00 숫자 4일 확률:0.00 숫자 5일 확률:0.00 숫자 6일 확률:0.00 숫자 7일 확률:1.00 숫자 8일 확률:0.00 숫자 9일 확률:0.00 |
|
- 예측한 결과(y_pred)와 실제 정답(y_test)을 비교하여 정확도를 계산하고 출력
|
y_pred_index = torch.argmax(y_prob, axis=1)
accuracy = (y_test == y_pred_index).float().sum()/len(y_test)*100
print(f'테스트 정확도는 {accuracy:.2f}%입니다!')
|
| 테스트 정확도는 95.83%입니다! |
'AI > 딥러닝' 카테고리의 다른 글
| 06. 비선형 활성화 함수 (0) | 2024.06.20 |
|---|---|
| 05. 딥러닝 (0) | 2024.06.20 |
| 03. 논리회귀 (단항, 다중) | 시그모이드(sigmoid) 함수 (0) | 2024.06.19 |
| 02. 선형 회귀(단항, 다중) | 경사하강법 (0) | 2024.06.18 |
| 01. 파이토치(Pytorch) (0) | 2024.06.18 |



