1.셀레니옴(Selenium)
셀레니옴은 브라우저를 컨트롤 할 수 있도록 지원하는 라이버러리
주로 웹 어플리케이션의 테스트 자동화, 웹 스크래핑, 웹 어플리케이션의 상호작용 및 데이터 수집을 위해 개발
- XPath: 기존의 컴퓨터 파일 시스템에서 사용하는 경로 표현식과 유시한 경로 언어
- Jupyter 노트북으로 실행하기
더보기
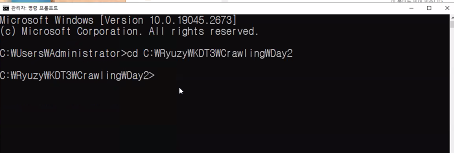

설치 안되어있으면 주피터설치
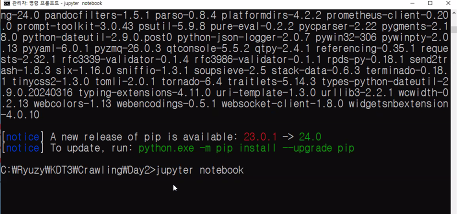

1. 경로설정
2. 주피터 노트북실행
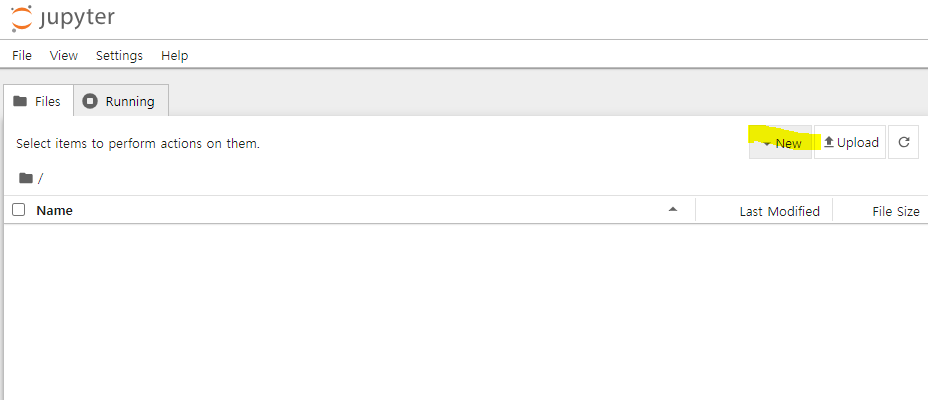
3. 새파일 생성
4. 이름변경
- 라이브러리 설치
! pip install selenium
- 모듈 설치
! pip install chromedriver_autoinstaller
- import
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
- Chrome 브라우저 실행
driver = webdriver.Chrome()
 |
- 구글페이지로 이동
 |
- 검색창 선택 후 검색창에 '날씨' 입력
search = driver.find_element('name','q')
search.send_keys('날씨')
search.send_keys('날씨')
더보기
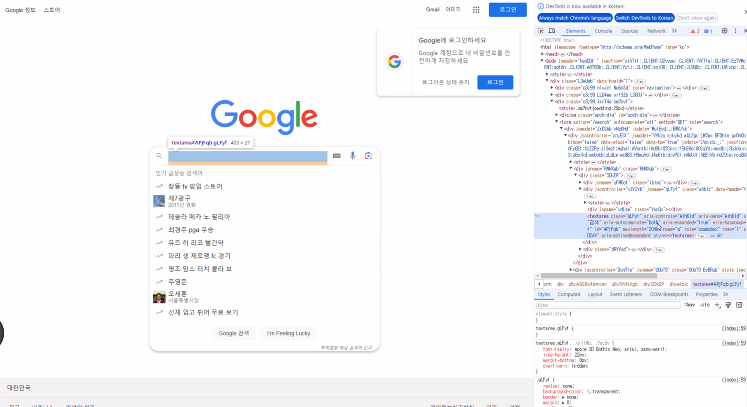

* 검색창 html 확인
 |
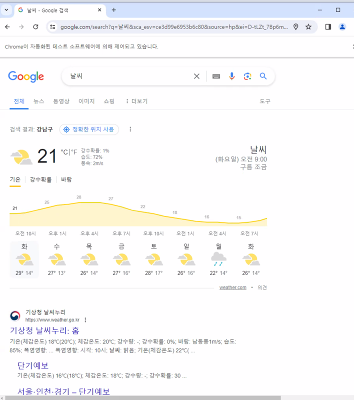
- 엔터키 클릭
search.send_keys(Keys.RETURN)

- 코드 정리
#정리
driver = webdriver.Chrome
driver.get('http://www.google.com')
search = driver.find_element('name','q')
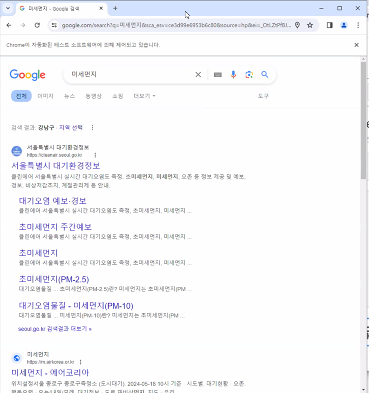
search.send_keys('미세먼지')
search.send_keys(Keys.RETURN)
driver = webdriver.Chrome
driver.get('http://www.google.com')
search = driver.find_element('name','q')
search.send_keys('미세먼지')
search.send_keys(Keys.RETURN)

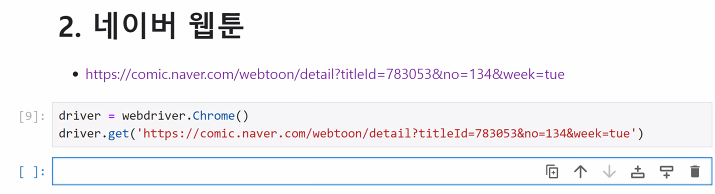
2. 네이버웹툰
댓글 가져오기
- 드라이버 설정
driver = webdriver.Chrome()
- bs4 설치
! pip install bs4f
- BeautifulSoup
from bs4 import BeautifulSoup
- 페이지 설정
#driver.page_source
soup = BeautifulSoup(driver.page_source)
#print(soup)
soup = BeautifulSoup(driver.page_source)
#print(soup)
| 해당 페이지 html 출력 |
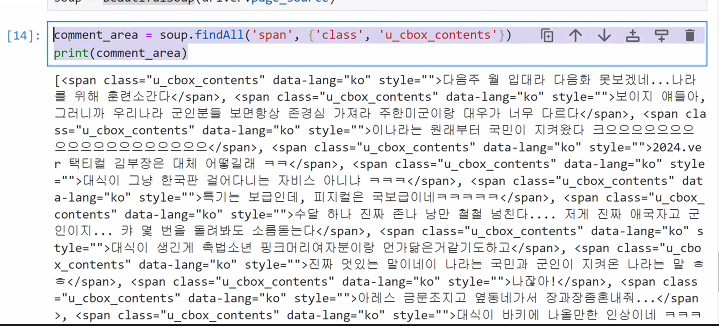
- 모든 댓글 출력
comment_area = soup.findAll('span', {'class','u_cbox_contents'})
print(comment_area)
더보기
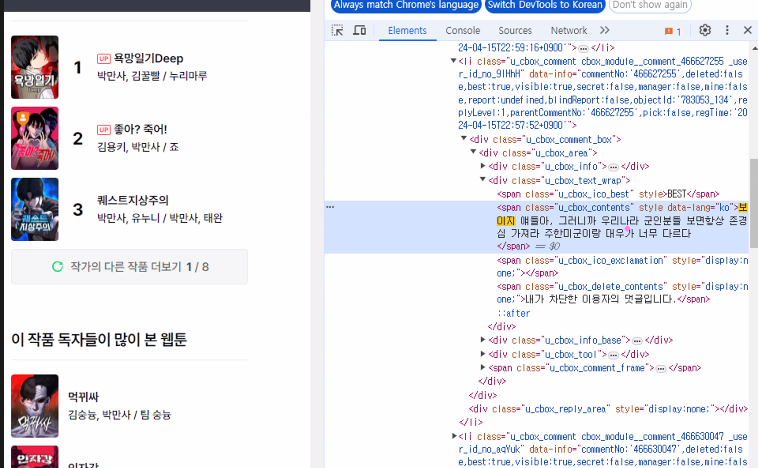
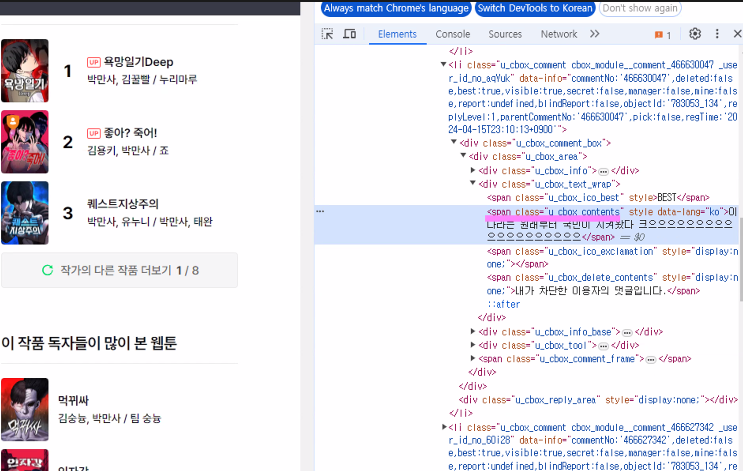
* html로 태그 확인
 |
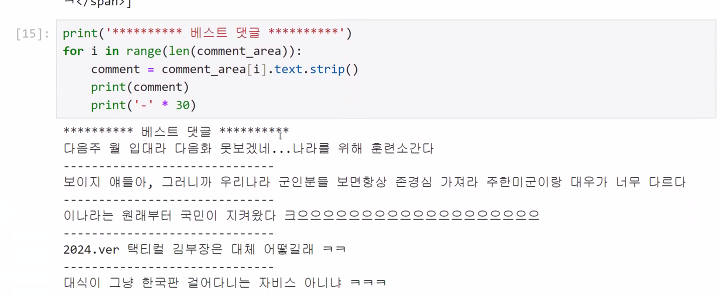
- 베스트 댓글 출력
print('********** 배스트 댓글 **********')
for i in range(len(conmment_area)):
comment = conmment_area[i].text.strip()
print(comment)
print('-' * 30)
 |
- 전체코드
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
soup = BeautifulSoup(driver.page_source)
comment_area = soup.findAll('span', {'class','u_cbox_contents'})
print('********** 배스트 댓글 **********')
for i in range(len(conmment_area)):
comment = conmment_area[i].text.strip()
print(comment)
print('-' * 30)
3. Xpath
- 선택된 element에서 오른쪽 마우스 -> copy -> copy full XPath
- Xpath: 기존의 컴퓨터 파일 시스템에서 사용하는 경로 표현식과 유사한 XML의 경로 언어
- /html/body/div[1]/div[5]/div/div/div[4]/div[1]/div[3]/div/div/div[8]/a/span[1]
- Xpath 가져오기
더보기

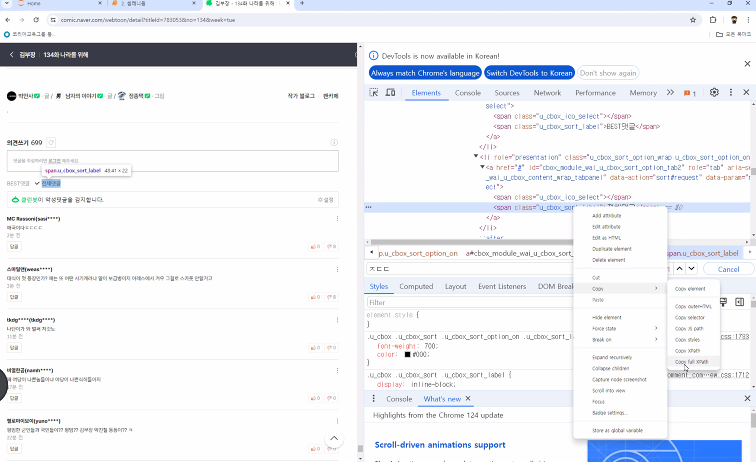
* 전체댓글 클릭시 active 활성화
* 전체댓글 태그 확인
* Xpath 가져오기
driver.find_element("xpath","/html/body/div[1]/div[5]/div/div/div[5]/div[1]/
div[3]/div/div/div[4]/div[1]/div/ul/li[2]/a/span[2]").click()
* 전체댓글 클릭됨 |
driver.find_element("xpath","/html/body/div[1]/div[5]/div/div/div[5]/div[1]/
div[3]/div/div/div[4]/div[1]/div/ul/li[2]/a/span[2]").click()
soup = BeautifulSoup(driver.page_source)
comment_area = soup.findAll("span", {"class": "u_cbox_contents"})
print(comment_area)

print('********** 전체 댓글 **********')
for i in comment_area:
print(i.text.strip())
print('-' * 30)

- 전체코드
driver.find_element("xpath","/html/body/div[1]/div[5]/div/div/div[5]/div[1]/div[3]
/div/div/div[4]/div[1]/div/ul/li[2]/a/span[2]").click()
soup = BeautifulSoup(driver.page_source)
comment_area = soup.findAll("span", {"class": "u_cbox_contents"})
print('********** 전체 댓글 **********')
for i in comment_area:
print(i.text.strip())
print('-' * 30)
'데이터분석 > 크롤링' 카테고리의 다른 글
| 04. 이미지 수집 (0) | 2024.05.21 |
|---|---|
| 03. 인스타그램 (0) | 2024.05.21 |
| 01. 크롤링(Crawling) (0) | 2024.05.20 |


