1. 크롤링과 스크레이핑
- 크로링(Crawling)
- 인터넷의 데이터를 활용하기 위해 정보들을 분석하고 활용할 수 있도록 수집하는 행위
- 스크레이핑(Scraping)
- 크로링 후 데이터를 추출하고 가공하는 행위
2. 실습: Basic English Speaking
- 75가지의 주제를 긁어와보기
- 사이트: https://basicenglishspeaking.com/daily-english-conversation-topics/
- requests 라이브러리
BeautifulSoup 라이브러리 사용하기
import requests
from bs4 import BeautifulSoup
- 'requests' 라이브러리를 사용
: 특정 웹 페이지에 요청을 보내고, 응답을 출력
request = requests.get(site)
print(request)
print(request.text)
| <Response [200]> 해당 사이트의 html, css, JavaScript 가 불러와짐 |
- BeautifulSoup 객체를 사용
: 특정 데이터를 추출
# 파싱: 원하는 데이터 뽑기
# 파싱할 수 있는 객체생성
soup = BeautifulSoup(request.text)
print(soup)
더보기


* HTML에서 크롤링하기 원하는 요소 찾아보기
| 해당 사이트의 html, css, JavaScript 가 불러와짐 |
- find(): 하나만 검색
# 원하는 div만 가져오기
divs = soup.find('div', {'class':'thrv-colums'})
print(divs)
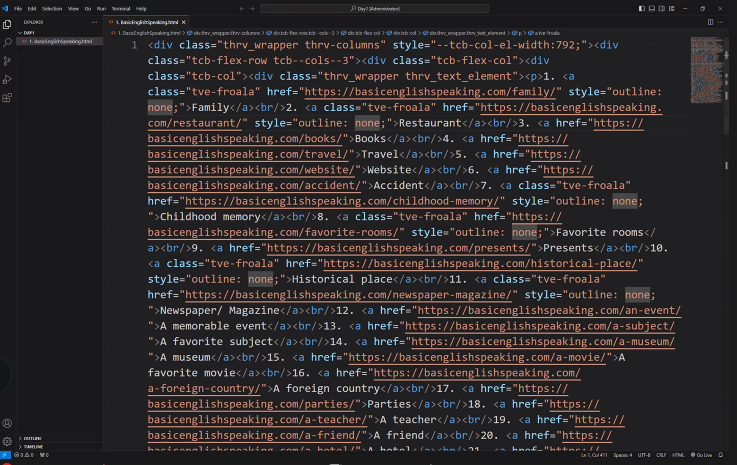
| 해당 div 가 불러와짐 |
- findAll() : 모두검색
# 앵커태그 배열로 가져오기
links = divs.findAll('a')
print (links)

| div 안에 있는 <a>가 불러와짐 |
- BeautifulSoup 라이브러리를 사용
: 웹 페이지에서 모든 링크 요소(<a> 태그)를 찾아 각 링크의 텍스트 내용을 출력
for link in links:
print(link.text)
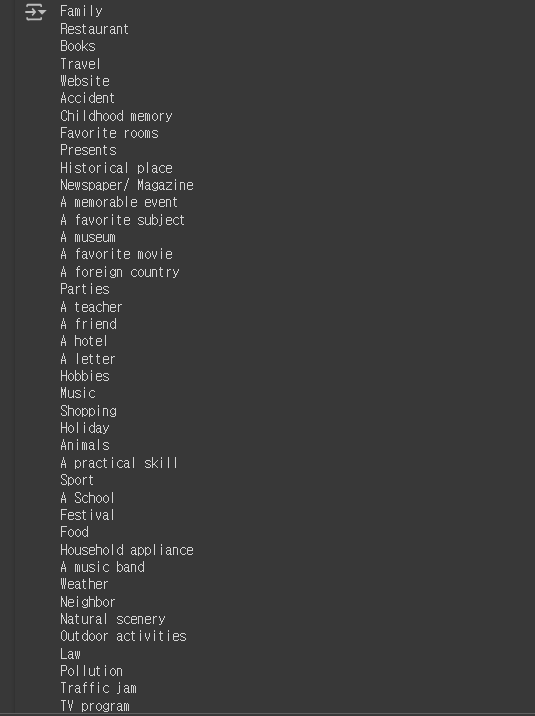
| 모든 <a>태그가 불러와짐 |
- BeautifulSoup 라이브러리를 사용
: 웹 페이지에서 모든 링크 요소(<a> 태그)를 찾아 각 링크의 텍스트 내용을 리스트에 저장하고,
그 리스트의 길이를 출력
subject = []
for link in links:
subject.append(link.text)
len(subject)
| 75 |
- 웹 페이지에서 추출한 링크 텍스트의 총 개수를 출력,
각 링크 텍스트를 인덱스와 함께 출력
print('총', len(subject), '개의 주제를 찾았습니다')
for i in range(len(subject)):
print('{0:2d},{1:s}'.format(i+1,subject[i]))

| 모든 <a> 태그가 번호가 부여되면서 불러와짐 |
3. 실습: 뉴스기사
- 뉴스기사에서 제목뽑기
- 뉴스기사 주소에 패턴이 있음
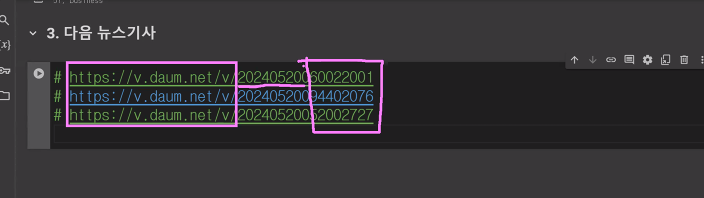
- 주소의 패턴 입력하면 '제목' 출력
def daum_news_title(news_id):
url = 'https://v.daum.net/v/{}'.format(news_id)
request = requests.get(url)
soup = BeautifulSoup(request.text)
title = soup.find('h3', {'class': 'tit_view'})
if title:
return title.text.strip()
return '제목 없음'
daum_news_title('20240520080317787')
daum_news_title('20240520100254886')
daum_news_title('20240520100752076')
| 오픈AI·구글에 MS도 맞불··· 빅테크 AI 대전 격화 ‘해외직구 금지’ 오락가락 정책에…소비자 “불신”·업계는 “불안” "K뷰티 날았다"…'1000억이상' 화장품 기업 12개로 껑충 |
4. 실습: 벅스뮤직차트
- 1-100위까지 곡제목과 아티스트 크롤링하기
- 사이트: https://music.bugs.co.kr/chart
- 벅스 뮤직 차트 : '곡제목' '아티스트' 출력
# Bugs 뮤직 차트 페이지 URL
request = requests.get("https://music.bugs.co.kr/chart")
# HTML 파싱
soup = BeautifulSoup(request.text)
# 노래 제목 추출
titles = soup.findAll('p', {'class': 'title'})
# 아티스트 이름 추출
artists = soup.findAll('p', {"class": 'artist'})
# 제목과 아티스트를 순서대로 출력
for i, (t, a) in enumerate(zip(titles, artists)):
# 제목 텍스트 처리
title = t.text.strip()
# 아티스트 텍스트 처리
artist = a.text.strip().split('\n')[0]
# 순위와 함께 출력
print("{0:3d}위 {1:s} - {2:s}".format(i+1, title, artist))

5. 실습: 멜론차트
- 1-100위까지 곡제목과 아티스트 크롤링하기
- requests 라이브러리를 사용하여 HTTP 요청
requests.get() 함수를 사용하여 Melon 차트 페이지에 GET 요청
더보기
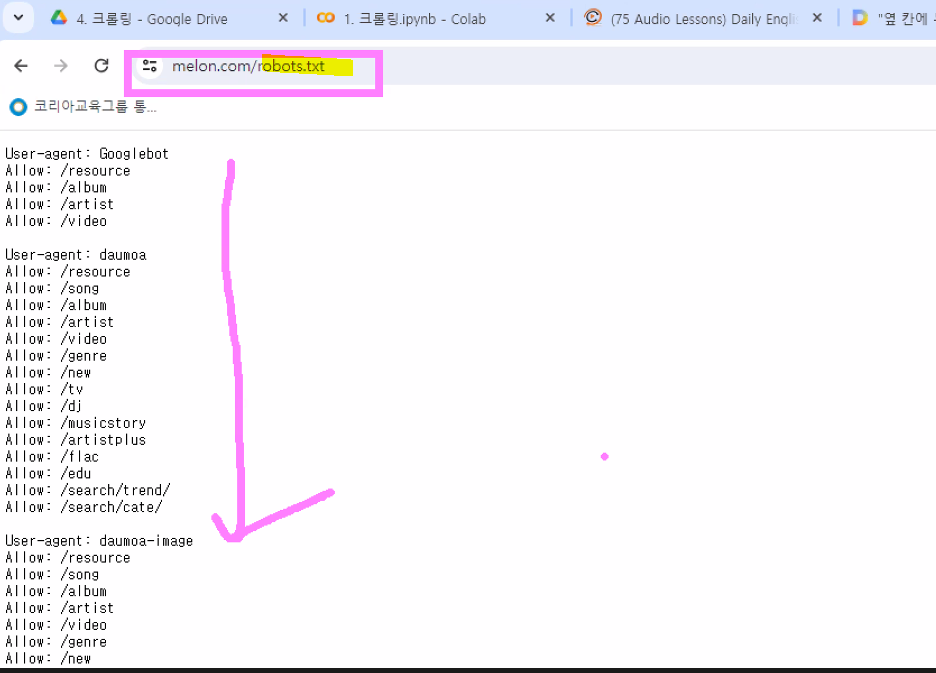

* 사이트 (주소/robots.txt)
크롤링 허용사항을 알 수 있음
* 이외에는 크롤링할 수 없음
| <Response [406]> |
- HTTP GET 요청을 보내고, 그 요청 객체를 출력
# User-Agent:
# Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36
# User-Agent 설정: 웹 브라우저를 통해 보낸 요청처럼 보이게 함
header = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'}
# Melon 차트 페이지에 GET 요청을 보냄
request = requests.get("https://www.melon.com/chart/index.htm", headers = header)
print(request)
더보기
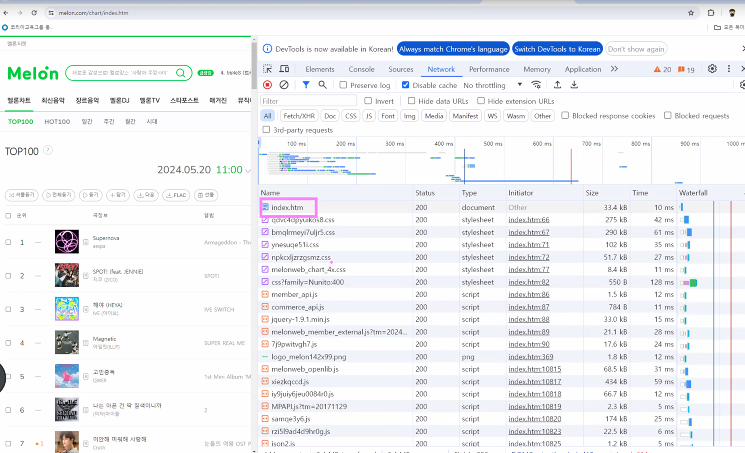
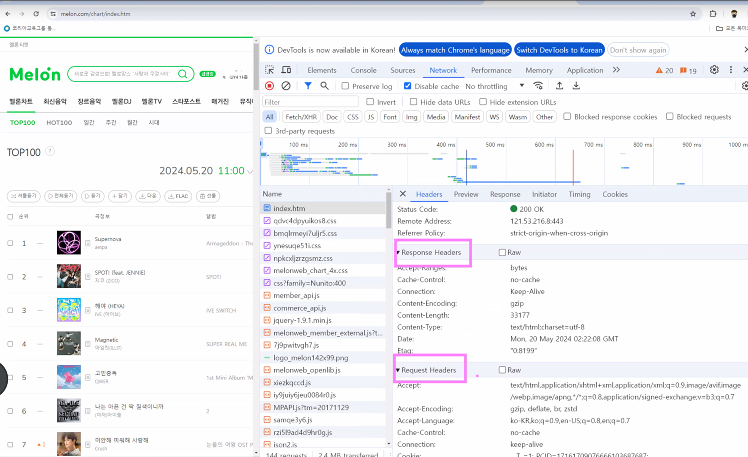

<해더 확인>
* 내 정보: User-Agent
| <Response [200]> |
- 멜론 차트 : '곡제목' '아티스트' 출력
# 웹 브라우저의 User-Agent 헤더를 추가하여 요청을 보냄
header = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'}
request = requests.get("https://www.melon.com/chart/index.htm", headers = header)
print(request)
soup = BeautifulSoup(request.text)
# 노래 제목 추출
titles = soup.findAll('div', {'class': 'rank01'})
# print(titles)
# 아티스트 이름 추출
artists = soup.findAll('span', {'class': 'checkEllipsis'})
for i, (t, a) in enumerate(zip(titles, artists)):
title = t.text.strip()
artist = a.text.strip()
print("{0:3d}위. {1:s} - {2:s}".format(i+1, title, artist))
 |
- 벅스뮤직
import requests
from bs4 import BeautifulSoup
for i in range(1, 5):
site = '{}{}'.format(url, i)
print(site)
genie = []
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'}
for i in range(1, 5):
site = '{}{}'.format(url, i)
request = requests.get(site, headers=header)
soup= BeautifulSoup(request.text, 'html.parser')
tbody = soup.find('tbody')
titles = tbody.findAll('a', {'class':'title'})
artists = tbody.findAll('a', {'class': 'artist'})
for i in range(50):
title = titles[i].text.strip()
artist = artists[i].text.strip()
genie.append((title, artist))
# 결과 출력
print("지니뮤직 TOP 200:")
for i, song in enumerate(genie, start=1):
print(f"{i}위. {song[0]} - {song[1]}")
6. 실습: 네이버 증권
- 주식정보크롤링하기
- 사이트: https://finance.naver.com/
- 네이버 증권에서 '이름', '가격', '종목코드', '거래량' 출력하기
# 이름, 가격, 종목코드, 거래량
# {'name':'경남제약, 'price':'1545', 'code':'053950', 'volumn':'1828172'}
import requests
from bs4 import BeautifulSoup
# 네이버 금융 페이지에서 주식 정보를 추출하는 함수 정의
def naver_finance(code):
request = requests.get(f"https://finance.naver.com/item/main.naver?code={code}")
soup = BeautifulSoup(request.text)
# 주식 정보를 담을 딕셔너리 생성
data_dict = {}
# 'new_totalinfo' 클래스를 가진 div 태그를 찾음
div_totalinfo = soup.find('div', {'class': 'new_totalinfo'})
# 주식 이름 추출
h2 = div_totalinfo.find('h2')
name = h2.text
# 현재 주가 추출
div_today = soup.find('div', {'class': 'today'})
price = div_today.find('span', {'class': 'blind'}).text
# 거래량 추출
table_no_info = soup.find('table', {'class': 'no_info'})
tds = table_no_info.findAll('td')
volumn = tds[2].find('span', {'class': 'blind'}).text
# 추출한 정보를 딕셔너리에 저장
dic = {'name': name, 'code': code, 'price': price, 'volumn': volumn}
return dic
# 함수 호출
naver_finance('025820')
naver_finance('032800')
| {'name': '이구산업', 'code': '025820', 'price': '8,250', 'volumn': '36,658,285'} {'name': '판타지오', 'code': '032800', 'price': '230', 'volumn': '23,850,469'} |
- naver_finance 함수를 반복적으로 호출,
이를 리스트에 저장한 후 출력
codes = ['032800','025820','114800','006910','032820']
data = []
for code in codes :
dic = naver_finance(code)
data.append(dic)
print(data)
| [{'name': '판타지오', 'code': '032800', 'price': '230', 'volumn': '24,335,440'}, {'name': '이구산업', 'code': '025820', 'price': '8,300', 'volumn': '38,938,021'}, {'name': 'KODEX 인버스', 'code': '114800', 'price': '4,120', 'volumn': '19,065,442'}, {'name': '보성파워텍', 'code': '006910', 'price': '4,020', 'volumn': '18,021,242'}, {'name': '우리기술', 'code': '032820', 'price': '2,025', 'volumn': '19,847,159'}] |
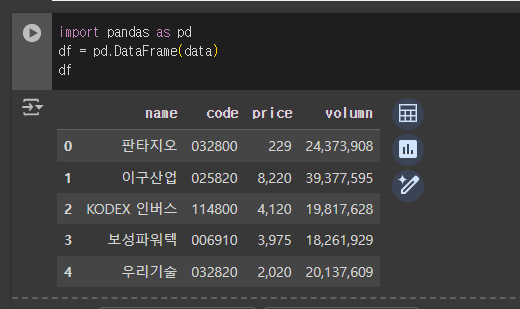
- 판다스로 출력하기
import pandas as pd
df = pd.DataFrame(data)
df
 |
- 엑셀로 추출하기
df.to_excel('naver_finance.xlsx')

 |
'데이터분석 > 크롤링' 카테고리의 다른 글
| 04. 이미지 수집 (0) | 2024.05.21 |
|---|---|
| 03. 인스타그램 (0) | 2024.05.21 |
| 02. Selenium, Xpath (네이버웹툰 크롤링) (0) | 2024.05.21 |


