더보기
CMD 창에서 입력
설치중

주피터 노트북
실행하면 그 해당 폴더를 중심으로 저장하거나 관리 실행됨, 위치가 중요
- 주피터 노트북 설치
1) 파이썬이 설치되어 있어야 함 (pip도 설치되어 있음)
2) pip install jupyter
(설치가 되지 않는 경우 pip install --upgrade pip 명령 실행 후 다시 설치)
3) 주피터 노트북 실행
(1) jupyter notebook --notebook-dir='C:\Ryuzy\Python'
(2) 원하는 디렉토리로 이동 후 실행
cd 내경로
jupyter notebook
- 주피터 노트북 단축키
셀 선택 모드(ESC)
a: 위에 새로운 셀 추가
b: 아래 새로운 셀 추가
c: 셀 복사하기
v: 셀 붙여넣기
x: 셀 잘라내구
dd: 셀 삭제하기
m: 마크다운으로 변경
y: 코드로 변경 - 셀 입력 모드(Enter)
컨트롤 + 엔터: 셀 실행
쉬프트 + 엔터: 셀 실행 후 아래 셀로 이동
알트 + 엔터: 셀 실행 후 아래 새로운 셀 추가
컨트롤 + a: 선택 셀 코드 전체 선택
컨트롤 + z: 선택 셀 실행 취소
컨트롤 + y: 선택 셀 다시 실행
컨트롤 + /: 커서 위치 주석 처리
1. 압축파일 정리하기
import os
import glob
import zipfile
import shutil
import fnmatch
import pathlib
# 현재 경로 알아보기
os.getcwd()
| 'C:\\Sarr\\KDT\\Python\\jupyter\\filemanager' |
# 정리대상 디렉토리 경로 설치하기 (폴더 지정)
target_path = './정리'
#'정리' 디렉토리에서 압축 파일 확인하기
zipfile_path = []
for filename in glob.glob(os.path.join(target_path,'**/*.zip')
zipfile_path.append(filename)
print(zipfile_path)
| ['./정리\\ 데이터저장_물류.zip'] |
# 압축파일 해제하기
for filename in zipfile_path:
with zipfile.ZipFile(filename) as myzip:
myzip.extractall('압축푸는곳')

# 압축파일 정보보기
for filename in zipfile_path :
with zipfile.ZipFile(filename) as myzip:
zipinfo = myzip.infolist()
print(zipinfo) #<=======
| [<ZipInfo filename='D_20220110_╡Ñ└╠┼═└·└σ_╣░╖∙_001.pdf' compress_type=deflate external_attr=0x20 file_size=13264 compress_size=12312>, <ZipInfo filename='D_20220110_╡Ñ└╠┼═└·└σ_╣░╖∙_002.pdf' compress_type=deflate external_attr=0x20 file_size=13264 compress_size=12312>, <ZipInfo filename='D_20220723_╡Ñ└╠┼═└·└σ_╣░╖∙_001.pdf' compress_type=deflate external_attr=0x20 file_size=13264 compress_size=12312>, <ZipInfo filename='D_20220723_╝╛┼═░í╡┐╟÷╚▓_╣░╖∙_002.pdf' compress_type=deflate external_attr=0x20 file_size=13264 compress_size=12312>] |
# 압축파일 변환해서 풀기
for filename in zipfile_path :
with zipfile.ZipFile(filename) as myzip:
zipinfo = myzip.infolist()
for info in zipinfo :
decode_name = info.filename.encode('cp437').decode('euc-kr') #언어 변환
info.filename = os.path.join(target_path, decode_name) # 경로 변경
myzip.extract(info) #바뀐 정보대로 압축을 풀어줘
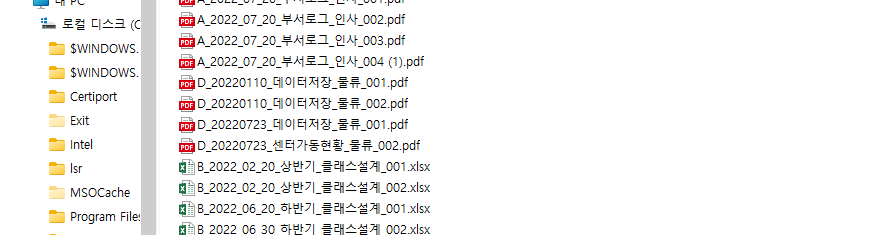
2. 엑셀파일 생성해서 수정하기
# openpyxl모듈 설치
!pip install openpyxl
| Requirement already satisfied: openpyxl in c:\users\administrator\appdata\local\programs\python\python310\lib\site-packages (3.1.2) Requirement already satisfied: et-xmlfile in c:\users\administrator\appdata\local\programs\python\python310\lib\site-packages (from openpyxl) (1.1.0) [notice] A new release of pip is available: 23.0.1 -> 24.0 [notice] To update, run: python.exe -m pip install --upgrade pip |
import openpyxl as opx
# 엑셀파일 생성
def getFileName(target_path) : # 경로를 './정리'로 설정
wb = opx.Workbook() #엑셀을 사용할 수 있는 객체 생성
ws = wb.active #작업모드
#셀만들고 값 넣기 .값 = ' '
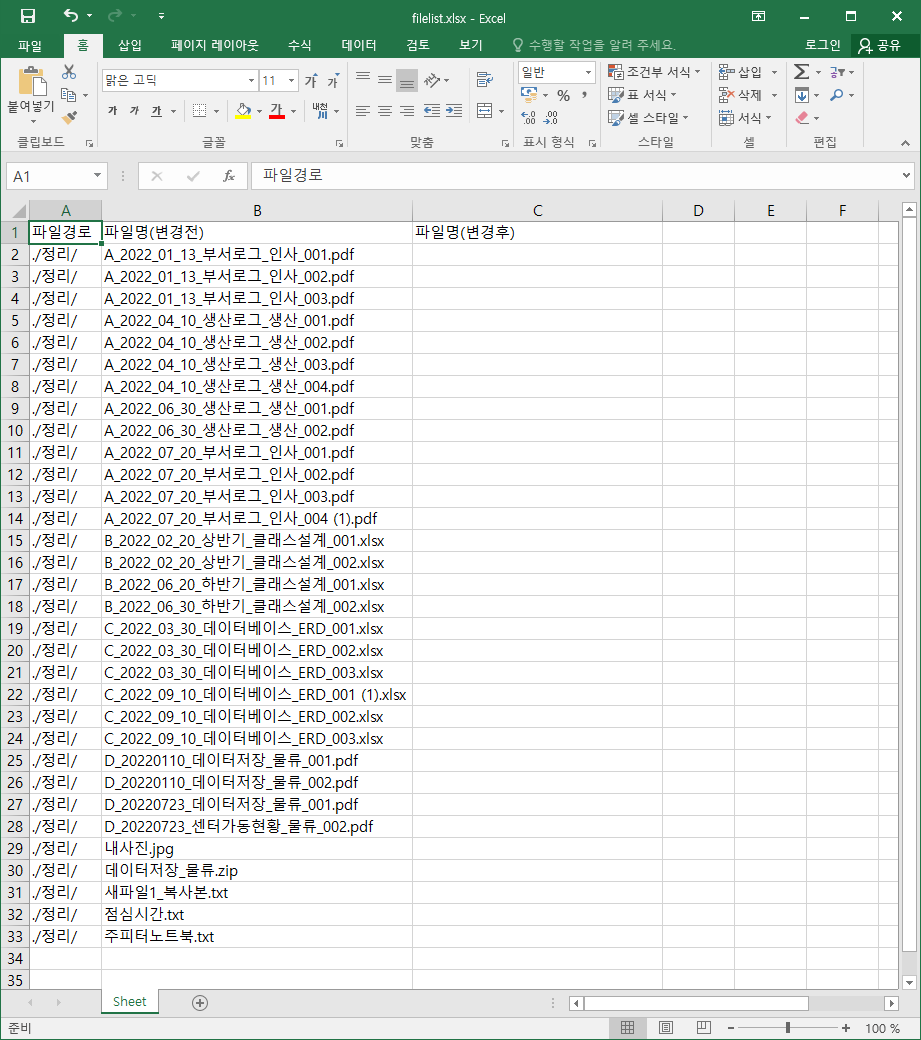
ws.cell(row=1, column=1).value = '파일경로'
ws.cell(row=1, column=1).value = '파일명(변경전)'
ws.cell(row=1, column=1).value = '파일명(변경후)'
i = 2
current_dir = target_path
filelist = os.listdir(current_dir) # filelist = 폴더 안에 있는 폴더이름을 정리한 것
for filename in filelist: # 파일갯수만큼 돌려
ws.cell(row=i, column=1).value = current_dir + '/' # 경로적기
ws.cell(row=i, column=2).value = filename # 이름적기
#저장하기 (해당경로, '파일명'으로 저장해줘)
wb.save(os.path.join(target_path, 'filelist.xlsx'))
getFileName(target_path)
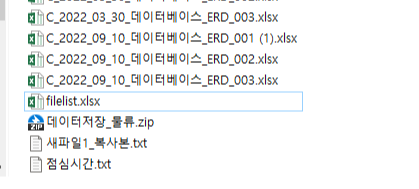
3. 파일명 변경하기
wb = opx.load_workbook(os.path.join(target_path, 'filelist.xlsx'))
ws = wb.active # 수정모드
dirpath = [r[0].value for r in ws] #r 다 가져옴 열의 0번
dirpath
['파일경로', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/', './정리/'] |
dirpath = [r[0].value for r in ws] # r : 열의 0번을 다가져오기
file_before = [r[1].value for r in ws]
print(file_before)
| ['파일명(변경전)', 'A_2022_01_13_부서로그_인사_001.pdf', 'A_2022_01_13_부서로그_인사_002.pdf', 'A_2022_01_13_부서로그_인사_003.pdf', 'A_2022_04_10_생산로그_생산_001.pdf', 'A_2022_04_10_생산로그_생산_002.pdf', 'A_2022_04_10_생산로그_생산_003.pdf', 'A_2022_04_10_생산로그_생산_004.pdf', 'A_2022_06_30_생산로그_생산_001.pdf', 'A_2022_06_30_생산로그_생산_002.pdf', 'A_2022_07_20_부서로그_인사_001.pdf', 'A_2022_07_20_부서로그_인사_002.pdf', 'A_2022_07_20_부서로그_인사_003.pdf', 'A_2022_07_20_부서로그_인사_004 (1).pdf', 'B_2022_02_20_상반기_클래스설계_001.xlsx', 'B_2022_02_20_상반기_클래스설계_002.xlsx', 'B_2022_06_20_하반기_클래스설계_001.xlsx', 'B_2022_06_30_하반기_클래스설계_002.xlsx', 'C_2022_03_30_데이터베이스_ERD_001.xlsx', 'C_2022_03_30_데이터베이스_ERD_002.xlsx', 'C_2022_03_30_데이터베이스_ERD_003.xlsx', 'C_2022_09_10_데이터베이스_ERD_001 (1).xlsx', 'C_2022_09_10_데이터베이스_ERD_002.xlsx', 'C_2022_09_10_데이터베이스_ERD_003.xlsx', 'D_20220110_데이터저장_물류_001.pdf', 'D_20220110_데이터저장_물류_002.pdf', 'D_20220723_데이터저장_물류_001.pdf', 'D_20220723_센터가동현황_물류_002.pdf', '내사진.jpg', '데이터저장_물류.zip', '새파일1_복사본.txt', '점심시간.txt', '주피터노트북.txt'] |
# excelRead(엑셀파일경로)의 이름으로 아래와 같이 값을 변환하는 함수를 만들어보자
# 단, 튜플로 (디렉토리, 변경전파일, 변경후파일) 나열되는 리스트를 변환
# 예) ('./정리/','A_2022_01_13_부서로그_인사_001.pdf','A_2022_01_13_부서로그_인사_001.pdf') ===> 튜플
# 예) ('./정리/','A_2022_01_13_부서로그_인사_002.pdf','A_2022_01_13_부서로그_인사_002.pdf') ===> 튜플
wb = opx.load_workbook(filepath)
ws = wb.active
dirpath = [r[0].value for r in ws]
file_before = [r[1].value for r in ws]
file_after = [r[2].value for r in ws]
datalist = []
for i in zip(dirpath, file_before, file_after):
datalist.append(i)
return datalist
excelRead(os.path.join(target_path, 'filelist.xlsx'))
#1행 빼고 출력
def excelRead(filepath):
wb = opx.load_workbook(filepath)
ws = wb.active
dirpath = [r[0].value for r in ws]
file_before = [r[1].value for r in ws]
file_after = [r[2].value for r in ws]
datalist = []
len_num = len(dirpath)
for i in range(1, len_num):
temp_tuple = (dirpath[i], file_before[i], file_after[i])
datalist.append(temp_tuple)
return datalist
rename_list = excelRead(os.path.join(target_path, 'filelist.xlsx'))
print(rename_list)
| [('파일경로', '파일명(변경전)', '파일명(변경후)'), ('./정리/', 'A_2022_01_13_부서로그_인사_001.pdf', 'A_2022_01_13_부서로그_인사_001.pdf'), ('./정리/', 'A_2022_01_13_부서로그_인사_002.pdf', 'A_2022_01_13_부서로그_인사_002.pdf'), ('./정리/', 'A_2022_01_13_부서로그_인사_003.pdf', 'A_2022_01_13_부서로그_인사_003.pdf'), ('./정리/', 'A_2022_04_10_생산로그_생산_001.pdf', 'A_2022_04_10_생산로그_생산_001.pdf'), ('./정리/', 'A_2022_04_10_생산로그_생산_002.pdf', 'A_2022_04_10_생산로그_생산_002.pdf'), ('./정리/', 'A_2022_04_10_생산로그_생산_003.pdf', 'A_2022_04_10_생산로그_생산_003.pdf'), ('./정리/', 'A_2022_04_10_생산로그_생산_004.pdf', 'A_2022_04_10_생산로그_생산_004.pdf'), ('./정리/', 'A_2022_06_30_생산로그_생산_001.pdf', 'A_2022_06_30_생산로그_생산_001.pdf'), ('./정리/', 'A_2022_06_30_생산로그_생산_002.pdf', 'A_2022_06_30_생산로그_생산_002.pdf'), ('./정리/', 'A_2022_07_20_부서로그_인사_001.pdf', 'A_2022_07_20_부서로그_인사_001.pdf'), ('./정리/', 'A_2022_07_20_부서로그_인사_002.pdf', 'A_2022_07_20_부서로그_인사_002.pdf'), ('./정리/', 'A_2022_07_20_부서로그_인사_003.pdf', 'A_2022_07_20_부서로그_인사_003.pdf'), ('./정리/', 'A_2022_07_20_부서로그_인사_004 (1).pdf', 'A_2022_07_20_부서로그_인사_004.pdf'), ('./정리/', 'B_2022_02_20_상반기_클래스설계_001.xlsx', 'B_2022_02_20_상반기_클래스설계_001.xlsx'), ('./정리/', 'B_2022_02_20_상반기_클래스설계_002.xlsx', 'B_2022_02_20_상반기_클래스설계_002.xlsx'), ('./정리/', 'B_2022_06_20_하반기_클래스설계_001.xlsx', 'B_2022_06_20_하반기_클래스설계_001.xlsx'), ... ('./정리/', '데이터저장_물류.zip', '데이터저장_물류.zip'), ('./정리/', '새파일1_복사본.txt', '새파일1.txt'), ('./정리/', '점심시간.txt', '점심시간.txt'), ('./정리/', '주피터노트북.txt', '주피터노트북.txt')] |
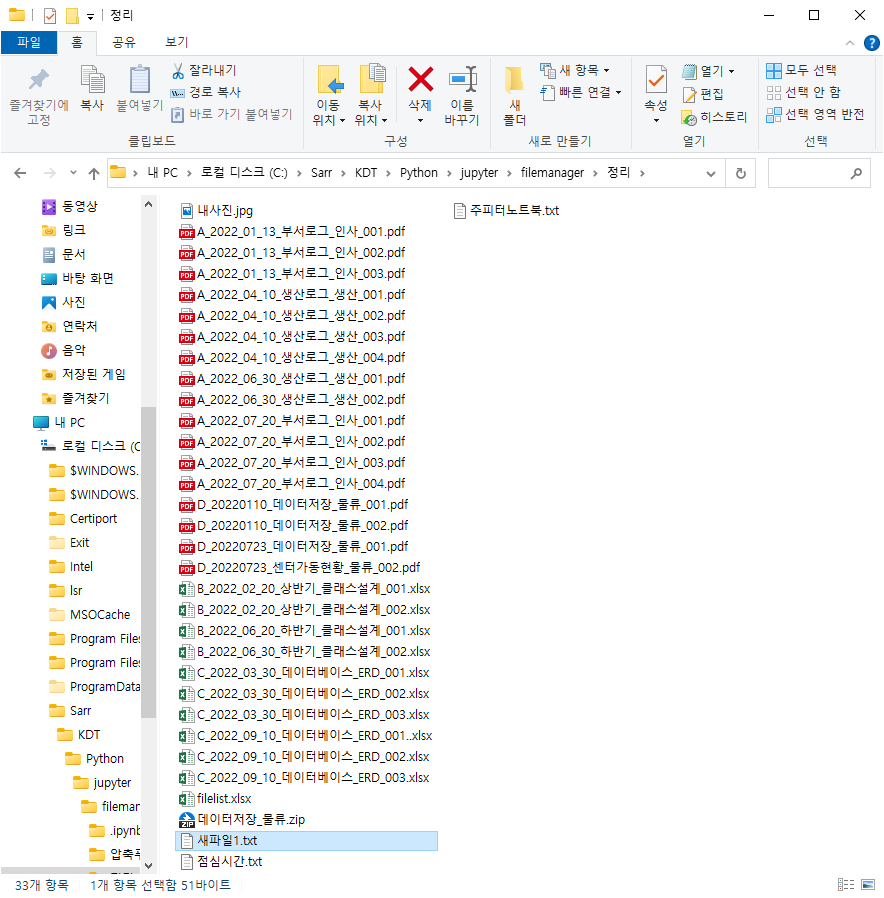
def fileRename(datalist) :
for data in datalist :
print(data[1] + '의 파일명' + data[2] + '로 변경합니다.')
shutil.move(data[0]+data[1], data[0]+data[2])
fileRename(rename_list)
| A_2022_01_13_부서로그_인사_001.pdf의 파일명을 A_2022_01_13_부서로그_인사_001.pdf로 변경합니다 A_2022_01_13_부서로그_인사_002.pdf의 파일명을 A_2022_01_13_부서로그_인사_002.pdf로 변경합니다 A_2022_01_13_부서로그_인사_003.pdf의 파일명을 A_2022_01_13_부서로그_인사_003.pdf로 변경합니다 A_2022_04_10_생산로그_생산_001.pdf의 파일명을 A_2022_04_10_생산로그_생산_001.pdf로 변경합니다 A_2022_04_10_생산로그_생산_002.pdf의 파일명을 A_2022_04_10_생산로그_생산_002.pdf로 변경합니다 A_2022_04_10_생산로그_생산_003.pdf의 파일명을 A_2022_04_10_생산로그_생산_003.pdf로 변경합니다 A_2022_04_10_생산로그_생산_004.pdf의 파일명을 A_2022_04_10_생산로그_생산_004.pdf로 변경합니다 A_2022_06_30_생산로그_생산_001.pdf의 파일명을 A_2022_06_30_생산로그_생산_001.pdf로 변경합니다 A_2022_06_30_생산로그_생산_002.pdf의 파일명을 A_2022_06_30_생산로그_생산_002.pdf로 변경합니다 A_2022_07_20_부서로그_인사_001.pdf의 파일명을 A_2022_07_20_부서로그_인사_001.pdf로 변경합니다 A_2022_07_20_부서로그_인사_002.pdf의 파일명을 A_2022_07_20_부서로그_인사_002.pdf로 변경합니다 A_2022_07_20_부서로그_인사_003.pdf의 파일명을 A_2022_07_20_부서로그_인사_003.pdf로 변경합니다 A_2022_07_20_부서로그_인사_004 (1).pdf의 파일명을 A_2022_07_20_부서로그_인사_004.pdf로 변경합니다 B_2022_02_20_상반기_클래스설계_001.xlsx의 파일명을 B_2022_02_20_상반기_클래스설계_001.xlsx로 변경합니다 B_2022_02_20_상반기_클래스설계_002.xlsx의 파일명을 B_2022_02_20_상반기_클래스설계_002.xlsx로 변경합니다 B_2022_06_20_하반기_클래스설계_001.xlsx의 파일명을 B_2022_06_20_하반기_클래스설계_001.xlsx로 변경합니다 B_2022_06_30_하반기_클래스설계_002.xlsx의 파일명을 B_2022_06_30_하반기_클래스설계_002.xlsx로 변경합니다 C_2022_03_30_데이터베이스_ERD_001.xlsx의 파일명을 C_2022_03_30_데이터베이스_ERD_001.xlsx로 변경합니다 C_2022_03_30_데이터베이스_ERD_002.xlsx의 파일명을 C_2022_03_30_데이터베이스_ERD_002.xlsx로 변경합니다 C_2022_03_30_데이터베이스_ERD_003.xlsx의 파일명을 C_2022_03_30_데이터베이스_ERD_003.xlsx로 변경합니다 C_2022_09_10_데이터베이스_ERD_001 (1).xlsx의 파일명을 C_2022_09_10_데이터베이스_ERD_001.xlsx로 변경합니다 C_2022_09_10_데이터베이스_ERD_002.xlsx의 파일명을 C_2022_09_10_데이터베이스_ERD_002.xlsx로 변경합니다 C_2022_09_10_데이터베이스_ERD_003.xlsx의 파일명을 C_2022_09_10_데이터베이스_ERD_003.xlsx로 변경합니다 D_20220110_데이터저장_물류_001.pdf의 파일명을 D_20220110_데이터저장_물류_001.pdf로 변경합니다 D_20220110_데이터저장_물류_002.pdf의 파일명을 D_20220110_데이터저장_물류_002.pdf로 변경합니다 D_20220723_데이터저장_물류_001.pdf의 파일명을 D_20220723_데이터저장_물류_001.pdf로 변경합니다 D_20220723_센터가동현황_물류_002.pdf의 파일명을 D_20220723_센터가동현황_물류_002.pdf로 변경합니다 내사진.jpg의 파일명을 내사진.jpg로 변경합니다 데이터저장_물류.zip의 파일명을 데이터저장_물류.zip로 변경합니다 새파일1_복사본.txt의 파일명을 새파일1.txt로 변경합니다 점심시간.txt의 파일명을 점심시간.txt로 변경합니다 주피터노트북.txt의 파일명을 주피터노트북.txt로 변경합니다 |
# 디렉토리 안에 파일을 확인하여 카테고리를 뽑아주는 함수를 만들어보자
# 파일 이름확인 후 패턴을 보고 패턴에 해당하는 카테고리에 넣어줌
# ['생산', '클래스설계', '물류', 'ERD', '인사']
# fnmatch.fnmath() 메서드를 사용
def categoryList(target_path) :
file_list = []
for filename in os.listdir(target_path):
if fnmatch.fnmatch(filename, '*_[0-9][0-9][0-9].*'):
file_list.append(filename)
category = []
for file in file_list :
temp_list = file.split('_') #['A','2022','01','13''부서로그''인사''001.pdf']
category.append(temp_list[-2])
category = set(category)
return list(category)
categoryList(target_path)
| ['인사', '생산', '물류', 'ERD', '클래스설계'] |
categorylist = categoryList(target_path) + ['기타']
print(categorylist)
| ['인사', '생산', '물류', 'ERD', '클래스설계', '기타'] |
new_path = './new_정리'
def makeDir(new_path, categorylist):
for category in categorylist:
new_dir = pathlib.Path(os.path.join(new_path, category))
new_dir.mkdir(parents=True, exist_ok=True)
# './new_정리' + '/클래스설게', '/물류', '/생산' ..
# parents: 상위 디렉토리가 없을 경우 상위 디렉토리도 생성
# exist_ok: 디렉토리가 이미 존재하는 경우 오류를 발생시키지 않도록 함
makeDir(new_path, categorylist)

4. 파일분류 및 이동하기(Shutil)
def shutilList(target_path) :
for filename in os.listdir(target_path):
if fnmatch.fnmatch(filename, '*생산*'):
shutil.move(os.path.join('정리',filename), os.path.join('new_정리/생산',filename))
elif fnmatch.fnmatch(filename, '*클래스설계*'):
shutil.move(os.path.join('정리',filename), os.path.join('new_정리/클래스설계',filename))
elif fnmatch.fnmatch(filename, '*물류*'):
shutil.move(os.path.join('정리',filename), os.path.join('new_정리/물류',filename))
elif fnmatch.fnmatch(filename, '*ERD*'):
shutil.move(os.path.join('정리',filename), os.path.join('new_정리/ERD',filename))
elif fnmatch.fnmatch(filename, '*인사*'):
shutil.move(os.path.join('정리',filename), os.path.join('new_정리/인사',filename))
else :
shutil.move(os.path.join('정리',filename), os.path.join('new_정리/기타',filename))
shutilList(target_path)
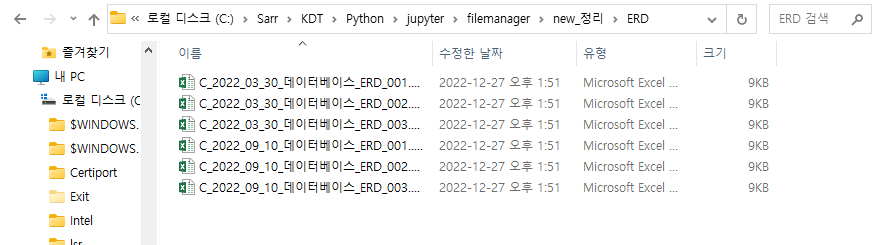
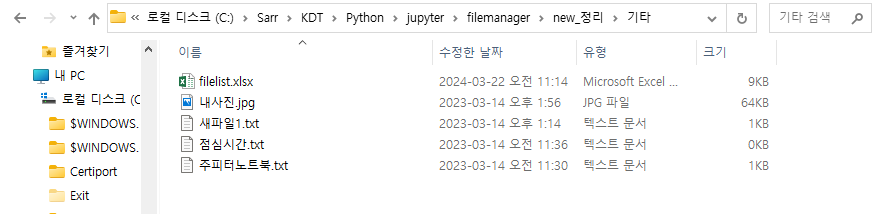
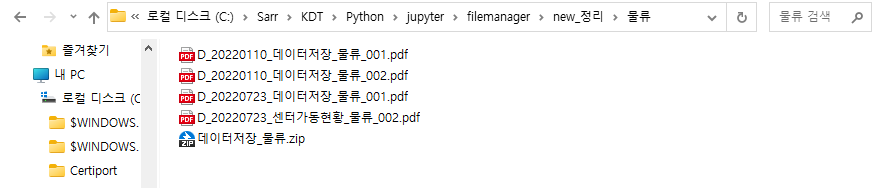

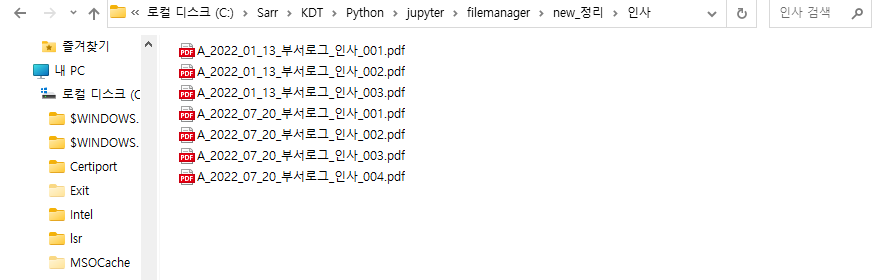
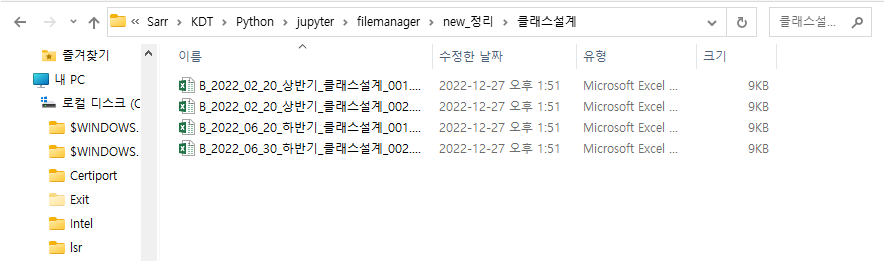
ㄴ 분류한 대로 이동한 것을 확인할 수 있습니다.
- assert
* 주어진 조건이 True 면 확인하고 조건이 False이면 예외를 발생시키는데 사용
* 주로 디버깅 및 데스트 목적으로 코드에서 사용
* 디버그 모드에만 동작되며, 배포시에는 작동되지 않음
#assert를 사용한 예
def moveFile(new_path, target_path, categorylist):
dirlist = os.listdir(new_path)
filelist = os.listdir(target_path)
categorydic = {}
for file in filelist:
try:
temp_list = file.split('_')
assert temp_list[-2] in categorylist
categorydic[file] = temp_list[-2] # {'파일명':'분류명'}
except:
categorydic[file] = '기타' # {'파일명':'기타'}
for key, value in categorydic.items():
shutil.copy(target_path + '/' + key, new_path + '/' + value)
moveFile(new_path, target_path, categorylist)
5. 과제
디렉토리 관리 프로그램을 참고하여 자신의 시나리오를 만들고 파일 관련된 프로그램을 작성해보자.
1. 디렉토리에서 모든 빈 디텍토리를 제거
2. 중복된 파일 제거
3. 팀별 > 항목별 파일 정리
'Python > 개념' 카테고리의 다른 글
| Day 9. 과제 _ 파일 입출력을 이용한 단어장 만들기 (0) | 2024.03.27 |
|---|---|
| Day 10. 과제: 디렉토리 관련 프로그램 (0) | 2024.03.24 |
| Day 9-2. 파일 입출력 라이브러리 (0) | 2024.03.21 |
| Day 9-1. 변수 타입 어노테이션 (0) | 2024.03.21 |
| Day 8-2. 파일 입출력 (0) | 2024.03.20 |



