1. OCR(Optical Character Recognition)
- 광학 문자 인식
- 영상나 문서에서 텍스트를 자동으로 인식하고 컴퓨터가 이행할 수 있는 텍스트 데이터로 변환하는 프로세스
- Tesseract, EasyOCR, PaddleOCR, CLOVA OCR(네이버 API), Cloud Vision(구글 API)..
◼ 테서렉트(Tesseract)
- 오픈 소스 OCR 라이브러리로 구글에서 개발하고 현재는 여러 커뮤니티에 의해 유지보수
- 사이트: https://github.com/UB-Mannheim/tesseract/wiki
Home
Tesseract Open Source OCR Engine (main repository) - UB-Mannheim/tesseract
github.com
- 설치방법



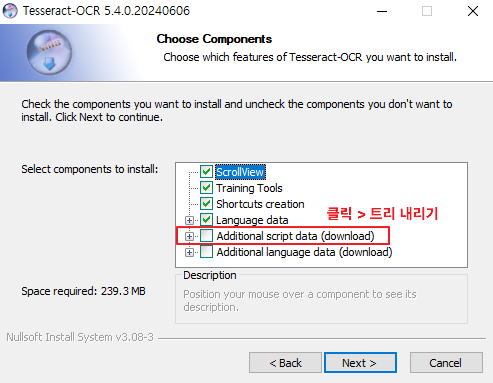


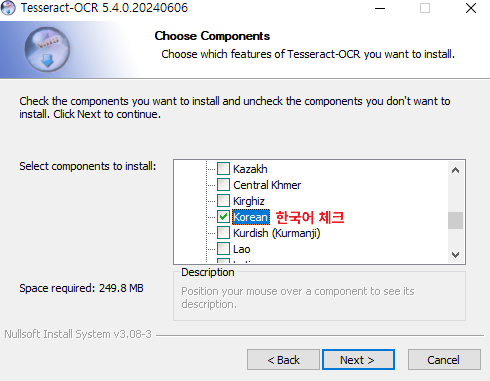

- 시스템 환경설정:
1. 탐색시 -> "내 PC" 에서 "속성 클릭" -> 창을 최대한 후에 우측 메뉴 "고급 시스템 설정" 클릭
없으면 검색창에 "시스템 속성" 검색
2. "환경 변수" 클릭 -> "시스템 변수"에서 path를 선택하고 "편집" 버튼 클릭 -> "새로 만들기" 버튼 -> 테서렉트 설치 경로를 추가("C:\Program Files\Tesseract-OCR")


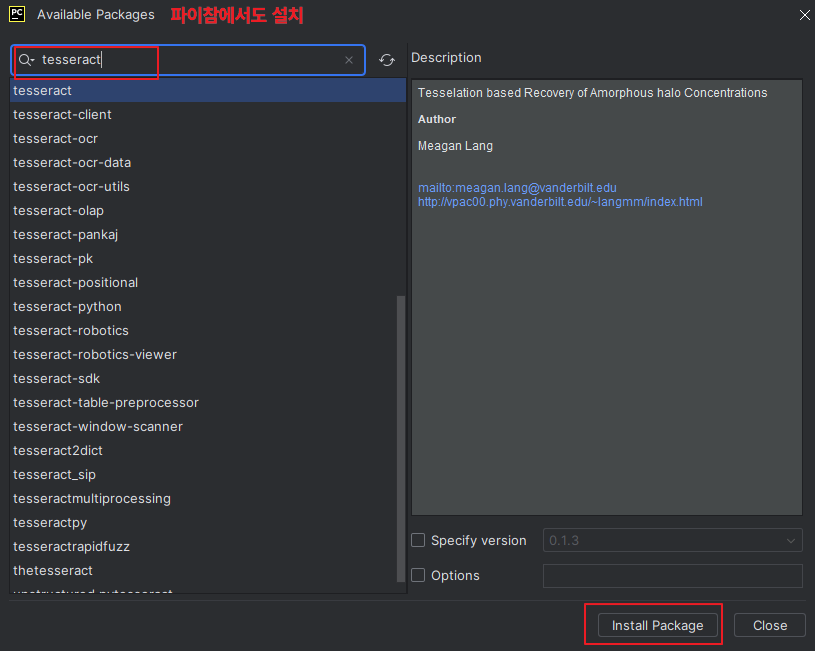

◼ 예제1 : 사진에서 텍스트 추출하기
|
import cv2
import pytesseract
img = cv2.imread('./hello.png')
dst = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 텍스트 추출
# pytesseract의 image_to_string() 함수를 사용하여 이미지에서 텍스트를 추출합니다.
# 'lang' 파라미터를 사용하여 OCR에 사용할 언어를 지정합니다. 'kor+eng'는 한국어와 영어를 의미합니다.
text = pytesseract.image_to_string(dst, lang='kor+eng')
print(text)
|
 |
◼ 예제2 : 사진에서 핀으로 일부분 캡쳐하고 텍스트 추출하기
|
import cv2
import numpy as np
import sys
import pytesseract
img = cv2.imread('./namecard.jpg')
h, w = img.shape[:2]
dh = 500
# A4용지 크기: 210*297mm
dw = round(dh * 297 / 210)
srcQuad = np.array([[30, 30], [30, h - 30], [w - 30, h - 30], [w - 30, 30]], np.float32)
dstQuad = np.array([[0, 0], [0, dh], [dw, dh], [dw, 0]], np.float32)
dragSrc = [False, False, False, False]
def drawROI(img, corners):
cpy = img.copy()
c1 = (192, 192, 255)
c2 = (128, 128, 255)
for pt in corners:
cv2.circle(cpy, tuple(pt.astype(int)), 25, c1, -1)
cv2.line(cpy, tuple(corners[0].astype(int)), tuple(corners[1].astype(int)), c2, 2)
cv2.line(cpy, tuple(corners[1].astype(int)), tuple(corners[2].astype(int)), c2, 2)
cv2.line(cpy, tuple(corners[2].astype(int)), tuple(corners[3].astype(int)), c2, 2)
cv2.line(cpy, tuple(corners[3].astype(int)), tuple(corners[0].astype(int)), c2, 2)
return cpy
def onMouse(event, x, y, flags, param):
global srcQuad, dragSrc, ptOld, img
if event == cv2.EVENT_LBUTTONDOWN:
for i in range(4):
if cv2.norm(srcQuad[i] - (x, y)) < 25:
dragSrc[i] = True
ptOld = (x, y)
break
if event == cv2.EVENT_LBUTTONUP:
for i in range(4):
dragSrc[i] = False
if event == cv2.EVENT_MOUSEMOVE:
for i in range(4):
if dragSrc[i]:
srcQuad[i] = (x, y)
cpy = drawROI(img, srcQuad)
cv2.imshow('img', cpy)
ptOld = (x, y)
break
disp = drawROI(img, srcQuad)
cv2.namedWindow('img')
cv2.setMouseCallback('img', onMouse)
cv2.imshow('img', disp)
while True:
key = cv2.waitKey()
if key == 13:
break
elif key == 27:
sys.exit()
pers = cv2.getPerspectiveTransform(srcQuad, dstQuad)
dst = cv2.warpPerspective(img, pers, (dw, dh), flags=cv2.INTER_CUBIC)
# 변환된 이미지에서 텍스트 추출
text = pytesseract.image_to_string(dst, lang='eng+kor')
print("Extracted Text:")
print(text)
cv2.imshow('dst', dst)
cv2.waitKey()
cam_mode = 0
while True:
ret, frame = cap.read()
if cam_mode == 1:
frame = blur_filter(frame)
elif cam_mode == 2:
frame = canny_filter(frame)
cv2.imshow('frame', frame)
key = cv2.waitKey(10)
if key == 27:
break
elif key == ord(' '):
cam_mode += 1
if cam_mode == 3:
cam_mode = 0
cap.release()
|
 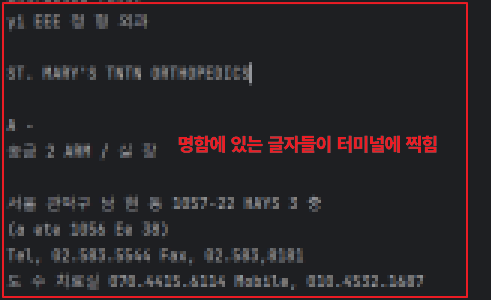 |
'AI > 컴퓨터 비전' 카테고리의 다른 글
| 13. Faster R-CNN | 객체 탐지 (0) | 2024.07.25 |
|---|---|
| 12. VGG19 | 분류 (1) | 2024.07.24 |
| 10. 레이블링 (2) | 2024.07.23 |
| 09. 모폴로지 변환 (0) | 2024.07.23 |
| 08. 필터링, 블러링 (0) | 2024.07.22 |



