data_transforms 딕셔너리는 학습 데이터(train)와 검증 데이터(validation)에 대해 서로 다른 전처리 과정을 정의합니다. transforms.Compose는 여러 전처리 과정을 순차적으로 적용할 수 있도록 합니다.
data_transforms는 학습과 검증 데이터를 위한 전처리 과정을 정의합니다.
학습 데이터: 이미지 크기 조정, 랜덤 어파인 변환, 랜덤 좌우 반전, 텐서 변환.
검증 데이터: 이미지 크기 조정, 텐서 변환.
target_transforms는 주어진 목표 값을 FloatTensor로 변환합니다.
이 설정을 통해 이미지 데이터를 모델에 입력하기 전에 일관된 크기와 형식으로 전처리할 수 있으며, 목표 값도 적절한 형식으로 변환할 수 있습니다.
데이터셋 로드
datasets.ImageFolder: 주어진 디렉토리 구조에서 이미지를 불러오기
이미지가 저장된 디렉토리 경로
이미지를 전처리하는 변환(transform) 함수
target_transform: 라벨(목표 값)을 변환하는 함수
DataLoader: 데이터셋을 배치 단위로 나누어 모델에 입력할 수 있도록 하는 PyTorch 클래스입니다 .
image_datasets['train']과 image_datasets['validation']을 각각 데이터 로더에 입력합니다.
batch_size=32: 배치 크기를 32로 설정합니다.
shuffle=True: 학습 데이터셋을 셔플하여 랜덤하게 배치를 만듭니다.
shuffle=False: 검증 데이터셋은 셔플하지 않습니다.
데이터셋 크기 출력:
len(image_datasets['train'])와 len(image_datasets['validation'])을 사용하여 학습 데이터셋과 검증 데이터셋의 이미지 개수를 출력합니다.
694 200
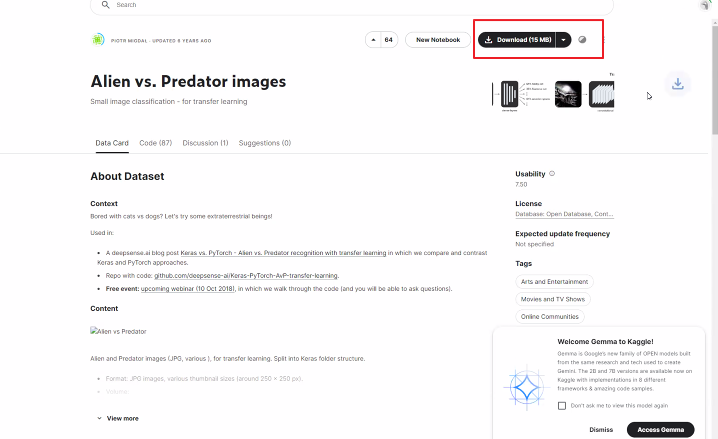
DataLoader를 사용하여 학습 데이터의 배치를 가져와서, 일부 이미지를 시각화
imgs, labels = next(iter(dataloaders['train']))
fig, axes = plt.subplots(4,8, figsize=(16,8))
for ax,img, label inzip(axes.flatten(), imgs, labels):
ax.imshow(img.permute(1,2,0))# (3, 224,224)
ax.set_title(label.item())
ax.axis('off')
학습 데이터 배치 가져오기:
iter(dataloaders['train']): 학습 데이터 로더의 반복자를 생성합니다.
next(iter(dataloaders['train'])): 반복자에서 첫 번째 배치를 가져옵니다. 이 배치는 이미지와 라벨로 구성됩니다.
imgs: 배치에 포함된 이미지들입니다.
labels: 배치에 포함된 이미지들의 라벨입니다.
플롯을 위한 서브플롯 설정:
plt.subplots(4, 8, figsize=(16, 8)): 4x8의 그리드(총 32개의 서브플롯)와 크기 16x8인 전체 플롯을 생성합니다.
fig: 전체 플롯을 나타내는 객체입니다.
axes: 개별 서브플롯을 나타내는 객체 배열입니다.
이미지 시각화:
axes.flatten(): 4x8 그리드를 1차원 배열로 평탄화하여 반복문에서 순차적으로 접근할 수 있게 합니다.
img.permute(1, 2, 0): PyTorch 텐서는 (채널, 높이, 너비) 순서이므로, 이를 (높이, 너비, 채널) 순서로 변경하여 imshow 함수가 인식할 수 있도록 합니다.
ax.set_title(label.item()): 각 서브플롯에 해당 이미지의 라벨을 제목으로 설정합니다.
ax.axis('off'): 각 서브플롯의 축을 비활성화하여 표시하지 않도록 합니다.
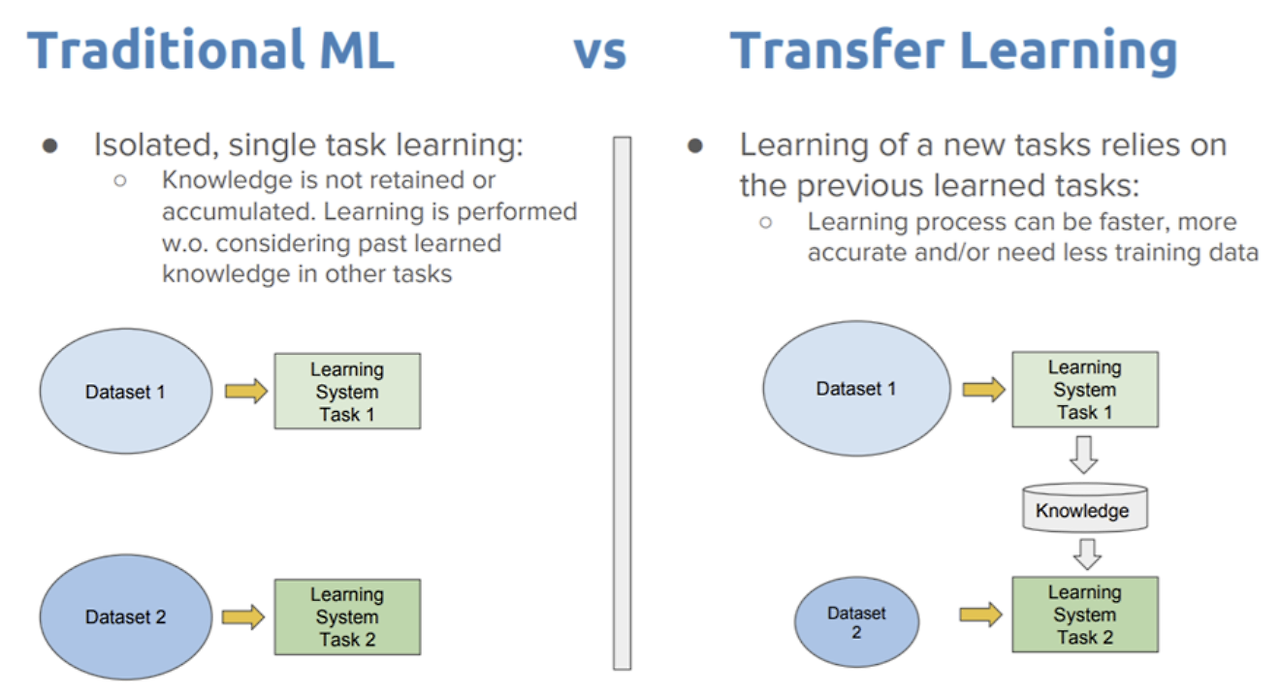
3. 전이 학습 (Transfer Learning)
* 하나의 작업을 위해 훈련된 모델을 유사 작업 수행 모델의 시작점으로 활용하는 딥러닝 접근법 * 신경망은 처음부터 새로 학습하는 것보다 전이학습을 통해 업데이트하고 재학습하는 편이 더 빠르고 간편함 * 전이 학습은 여러 응용 분야 중에서도 특히 검출, 영상 인식, 음성 인식, 검색분야에 많이 사용
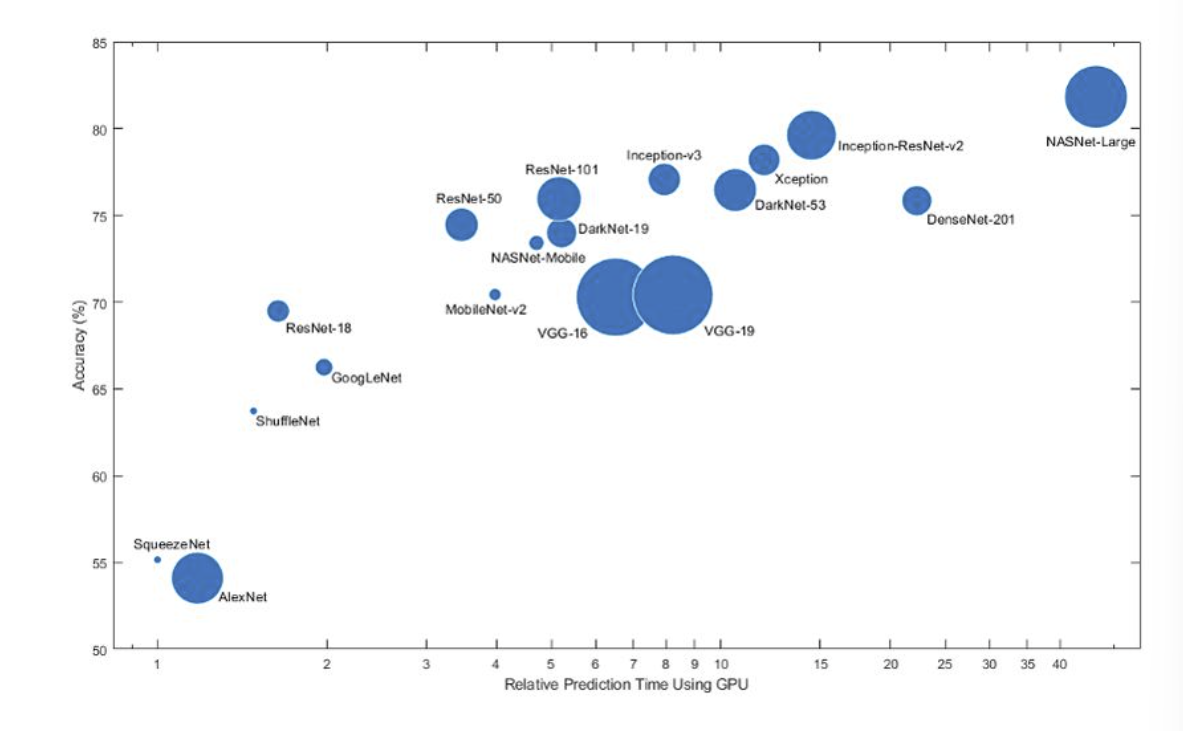
1. 전이학습의 고려할 점
- 크기 : 모델 크기의 중요성은 모델을 배포할 위치와 방법에 따라 달라짐 - 정확도: 재훈련 전의 모델 성능은 어느 정도인지 확인이 필요 - 예측 속도: 하드웨어 및 배치 크기와 같은 다른 딥러닝 요소는 물론 선택된 모델의 아키텍쳐와 모델 크기에 따라서도 달라짐
avg_loss = sum_losses / len(dataloaders[phase]), avg_acc = sum_accs / len(dataloaders[phase]): 전체 단계(phase)에 대한 평균 손실과 정확도를 계산합니다.
print(...): 각 단계(phase)의 에폭, 평균 손실, 평균 정확도를 출력하여 모델의 학습 진행 상황을 모니터링합니다.
요약
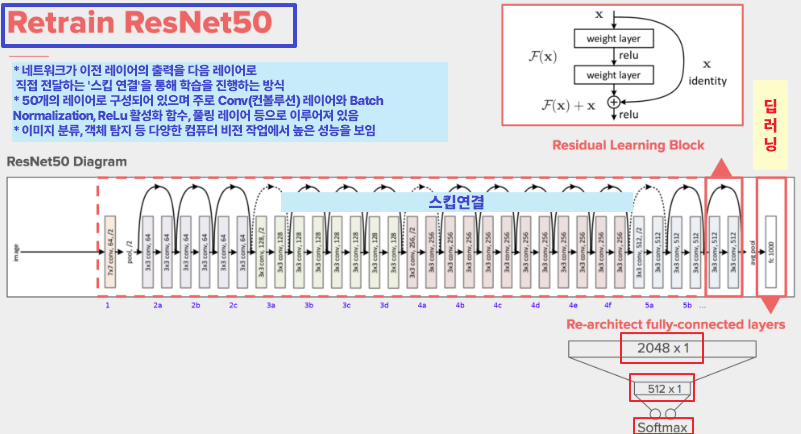
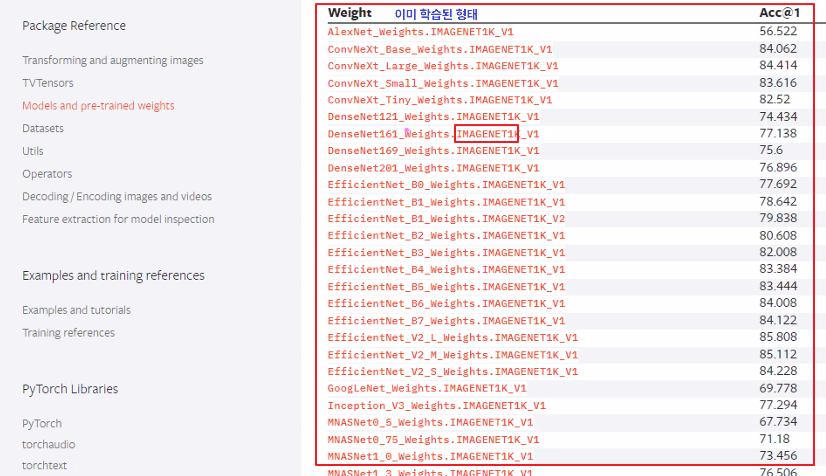
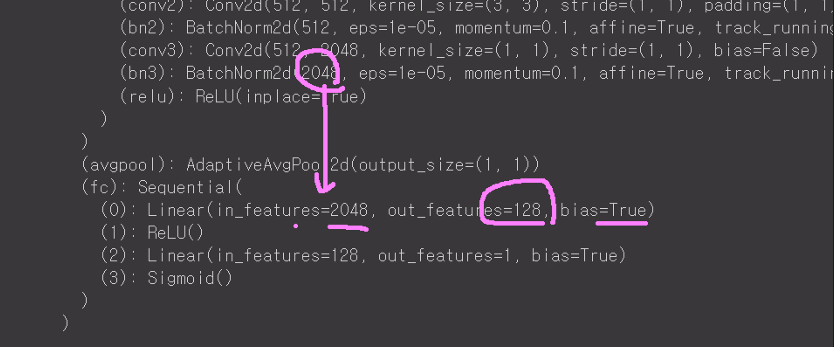
이 코드는 ResNet-50 모델의 마지막 fully connected 레이어만을 학습하면서 이진 분류를 수행하는 과정을 보여줍니다. 학습과 검증 과정에서 손실과 정확도를 계산하고, Adam 옵티마이저를 사용하여 모델 파라미터를 업데이트합니다. 이를 통해 모델을 효율적으로 학습시키고 학습 진행 상황을 모니터링할 수 있습니다.